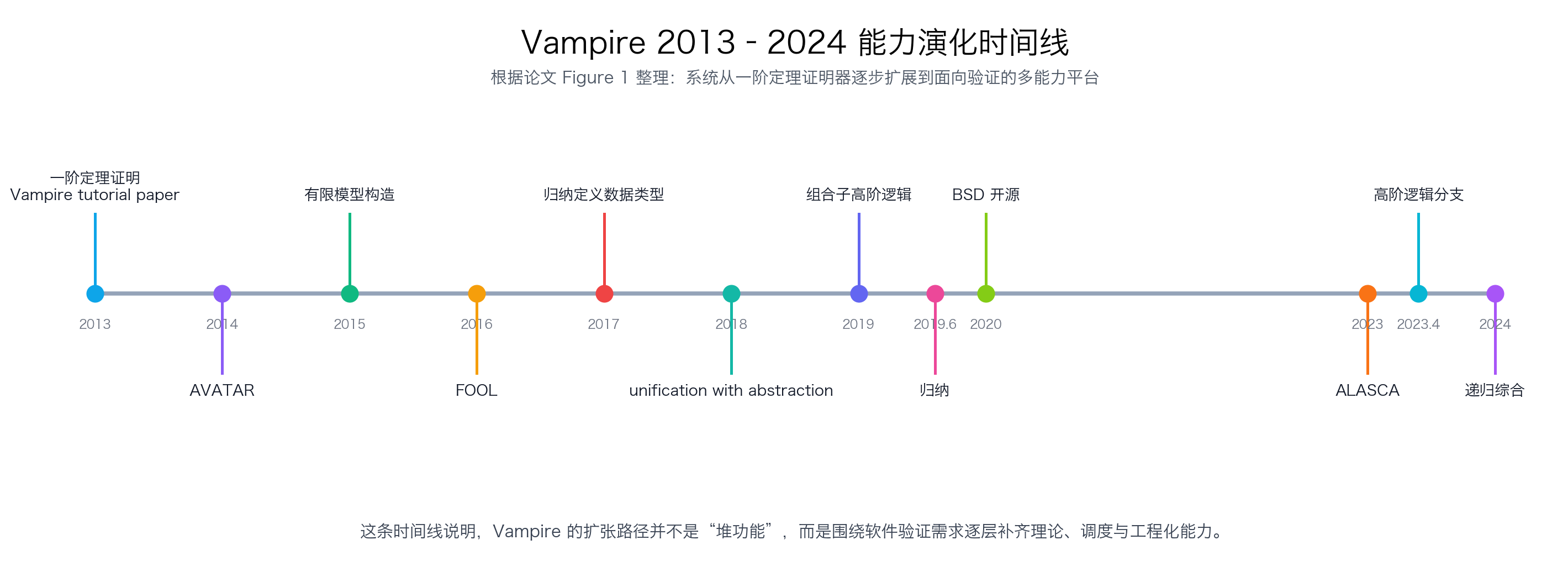
The Vampire Diary:Vampire 作为面向软件验证的统一推理平台
The Vampire Diary
这篇 CAV 2025 工具论文不是一次功能罗列,而是一次系统性回顾:Vampire 如何在保留 superposition / saturation 主循环的同时,把 ALASCA 算术、归纳、FOOL、多态逻辑、AVATAR、SAT/SMT 委派与 Spider 调度组织进统一架构。论文最有价值的地方,不是某个局部技巧,而是证明量词推理、ground theory reasoning 与策略学习可以被清晰分层、协同求解并长期演化。
论文概览
原文链接: arXiv 2506.03030
项目主页: Vampire
代码仓库: github.com/vprover/vampire
主题: 自动定理证明、饱和式证明搜索、软件验证、算术与归纳推理
《The Vampire Diary》本质上是一篇系统论文式的工具回顾。与其把它理解为“Vampire 又新增了哪些功能”,不如把它看成对一个核心问题的回答:以 superposition 为中心的饱和式 ATP,能否在不丢失量词推理优势的前提下,吸收理论推理、归纳、SAT/SMT 协作和策略学习,从而进入现代软件验证工作流。
论文给出的答案是肯定的,而且路线相当清晰:Vampire 没有把原有证明核心替换成另一类求解架构,而是围绕主循环逐步分层,引入可委派的布尔求解、ground theory reasoning、可扩展的逻辑前端,以及面向大规模参数空间的 schedule 学习。这个判断很重要,因为它说明 Vampire 的演化不是“不断加插件”,而是在维持系统统一性的前提下扩张边界。
其主线仍可写成:
但与 2013 年的工具版本相比,这条流水线已经不再对应单一推理机,而是一个围绕量词主循环组织起来的协作式证明栈。
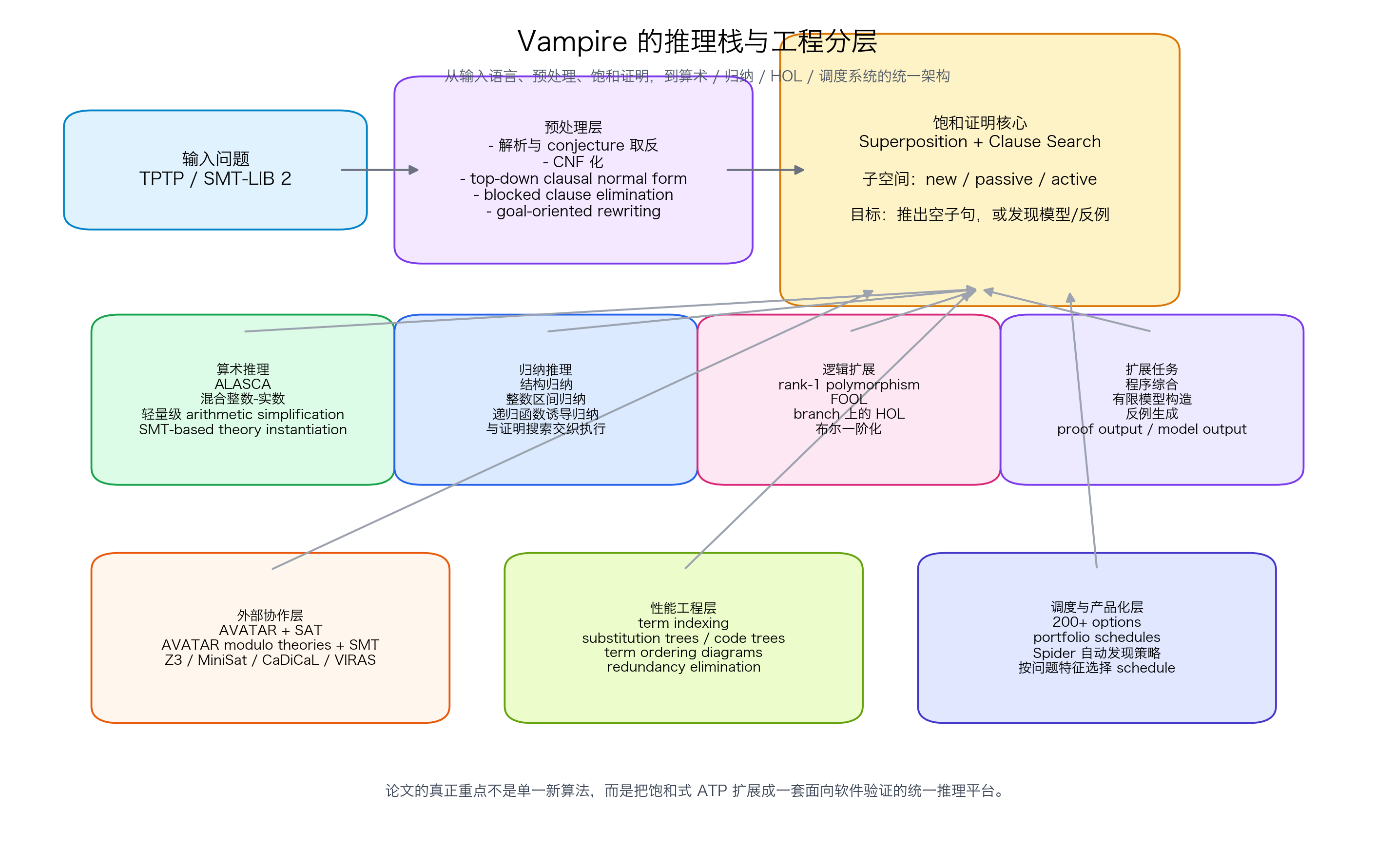
系统贡献:从一阶 ATP 到验证推理平台
1. 用 ALASCA 把量化算术接入主证明循环
论文首先强调的是算术能力。传统 superposition 在纯等式推理上很强,但面对带量词的线性算术时往往需要额外结构。Vampire 通过 ALASCA(Abstracting Linear Arithmetic Superposition Calculus)把不等式链、带抽象的合一、模线性算术重写等机制纳入主循环,使量化算术不再只是外围补丁,而成为原生 calculus 的一部分。
沿着这条路线,系统还进一步支持:
- 混合整数-实数算术;
- 借助量词消去处理更复杂的组合情形;
- 以轻量级 arithmetic simplification / generalization 补足不必全面启用 ALASCA 的场景;
- 在 ground arithmetic 上,必要时通过 Z3 做 theory instantiation 或 AVATAR modulo theories。
这一设计选择的关键含义是:Vampire 仍把量词推理和主要证明责任保留在饱和式框架内部,只把更适合外部处理的局部 theory 任务委派出去。 这使它与纯 SMT 求解器保持了结构性差异:SMT 更擅长 theory reasoning,而 Vampire 试图在保留量词搜索优势的同时吸收 theory 求解能力。
2. 把归纳实现为推理规则,而非外置 tactic
论文的第二个核心进展是归纳。Vampire 支持:
- 归纳定义数据类型上的结构归纳;
- 整数有界区间上的归纳;
- 从递归函数定义生成的良基归纳原则。
更重要的是,这些归纳不是系统外部单独触发的一次性 tactic,而是通过理论引理生成与标准证明搜索交织执行。论文特别指出,Vampire 可以在搜索过程中处理大规模归纳公式,并把归纳与 superposition、简化和分裂共同调度。
这件事的系统意义很大。许多工具“支持归纳”的意思,是可以调用一个模板;而 Vampire 的做法是把归纳纳入核心搜索空间管理,因此它在示例问题中能够同时处理:多态列表、递归函数、实数算术和结构归纳。这种“组合推理”能力,比单独在某个 benchmark 上提高一点分数更重要。
3. 逻辑表达能力向验证需求持续扩张
论文回顾的第三条主线,是输入与表示层的扩展:
- rank-1 polymorphism:支撑参数化数据结构与多态理论;
- FOOL:把
if-then-else、let-in和 first-class Boolean 等验证常用结构更自然地带入一阶逻辑; - higher-order logic branch:在保留一阶饱和框架的同时扩展高阶推理;
- program synthesis:从关系型规格中边证明边构造程序。
如果只看功能清单,这容易被误读为“不断加新语法”。但从系统论文视角看,真正重要的是:现代软件验证需要的不是一个只会 refute clause set 的证明器,而是一个能够接受更接近程序语义的表达,并与模型构造、反例生成和综合能力协同工作的统一推理平台。
系统结构与运行机制:按 CAV 系统论文视角重拆
1. 两阶段工作流:表示变换先行,饱和搜索收尾
Vampire 的总体工作流仍然保持清晰的两阶段结构:
- 解析输入,若存在 conjecture 则先取反;
- 转为 CNF,并执行预处理;
- 在 clause 空间中做饱和搜索,尝试导出空子句;
- 若无法 refute,则可能报告 satisfiable、CounterSatisfiable 或构造有限模型。
论文将内部子句空间写成:
其中,新生成子句先进入 new,经化简后进入 passive,再被选作推理前提转入 active。这套组织本身不新,但在 Vampire 当前语境下,其含义已经变化:算术、归纳、HOL、模型构造和调度能力都必须围绕同一个 clause lifecycle 协同工作。 也就是说,系统性能不再主要取决于单条 inference rule,而取决于多种机制是否能在统一搜索空间中保持低摩擦协作。
2. 预处理不是附属模块,而是搜索空间压缩器
在 “Making It Work” 一节中,论文把相当篇幅留给预处理,这非常像成熟系统论文的写法,因为它承认性能瓶颈往往在进入 calculus 之前就已经决定。Vampire 新增或强化了:
- top-down clausal normal form;
- blocked clause elimination;
- 从 Twee 借鉴的 goal-oriented rewriting;
- 尽量保持线性时间复杂度、避免递归造成的栈溢出风险。
这里的核心判断是:自动定理证明系统的上限,不只取决于核心 calculus 的理论强度,还取决于输入在进入 calculus 之前被压缩得多干净。 对系统构建者来说,这比“是否又多支持一个理论片段”更值得记住。
3. AVATAR 与 SMT delegation:把布尔结构和 ground theory 交给更合适的求解层
Vampire 工程上最成熟的一条线仍然是 AVATAR。论文将其描述为:把问题的“命题本质”切分出来交给 SAT 求解器;在 AVATAR modulo theories 中,则进一步把 ground theory 子问题交给 SMT 求解器。
可以把论文的责任分配写成:
其中:
\mathcal{P}_{\mathrm{quantifier}}由 Vampire 的 superposition / saturation 主循环原生处理;\mathcal{P}_{\mathrm{propositional}}通过 AVATAR 委派给 SAT;\mathcal{P}_{\mathrm{ground\ theory}}通过 AVATAR modulo theories 或 theory instantiation 委派给 SMT(如 Z3)。
这是一种非常稳健的系统边界划分:它既没有把整套证明任务完全外包给 SMT,也没有坚持“所有问题都必须在单一 calculus 内部硬算完”。因此,Vampire 保留了量词和归纳的主场优势,同时在布尔分裂与 ground theory reasoning 上借用 SAT/SMT 的成熟基础设施。
4. 一张图看清 Vampire 的协作式推理剖面
下面这张补图,把论文里最关键的协作关系拆开了:superposition 核心、AVATAR/SAT 层、SMT delegation 和 Spider schedule 并不是彼此替代的组件,而是围绕同一条 clause pipeline 协同工作。
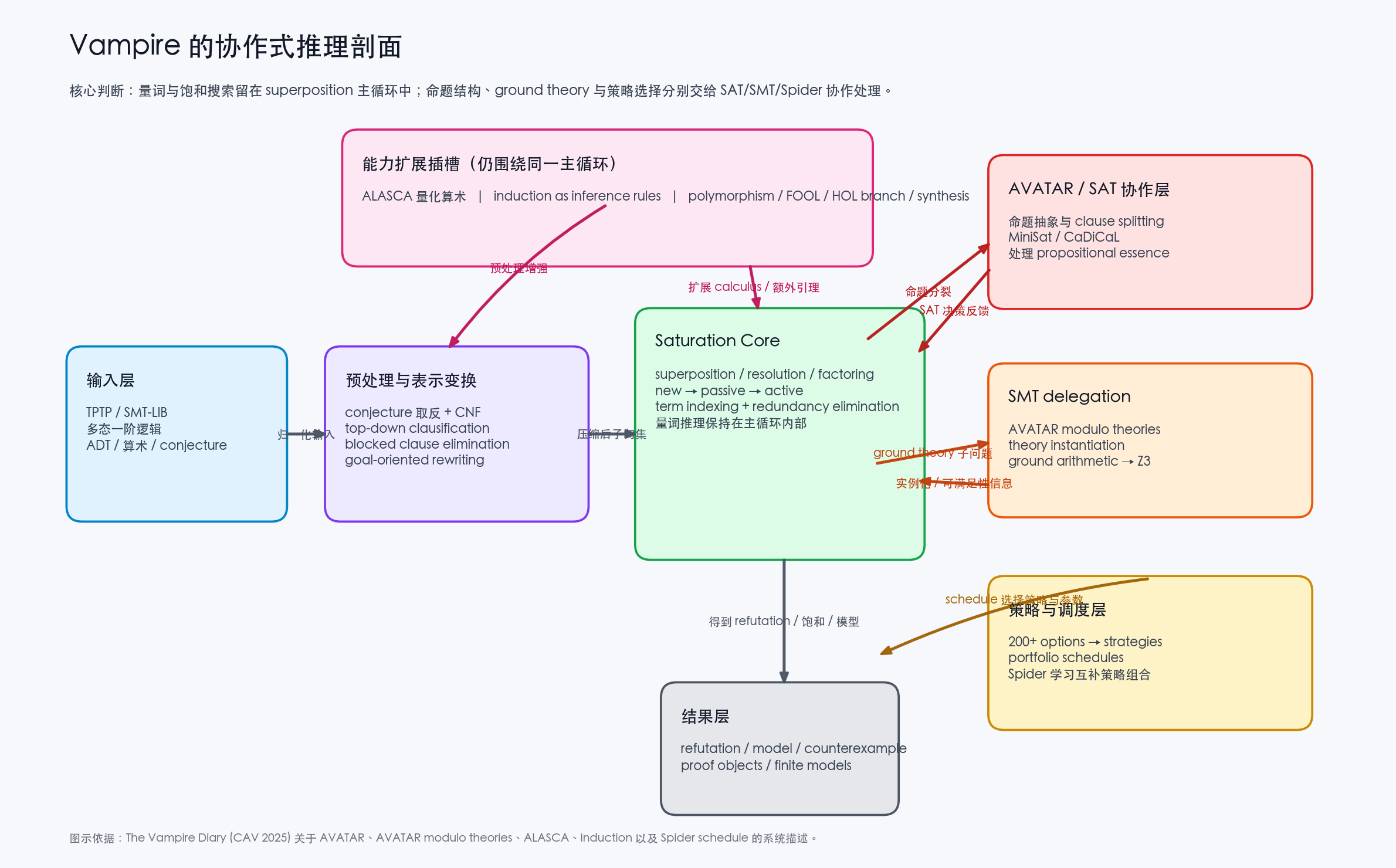
从这张图可以清楚看到,Vampire 的设计哲学不是“把所有能力塞进一个求解器里”,而是做三层责任划分:
- 量词和主要证明责任留在主循环中;
- 命题结构与 ground theory 子问题按边界委派给 SAT/SMT;
- 策略选择由 schedule 学习系统吸收超大参数空间的不确定性。
这也是本文最值得注意的系统命题:Vampire 的统一性来自核心证明范式,而不是来自拒绝协作。
5. 冗余消除与索引结构,决定系统是否真正可用
在系统论文里,最容易被忽视的往往是数据结构,但这恰恰是可扩展性的底盘。Vampire 使用:
- substitution trees;
- code trees;
- term ordering diagrams;
- SAT-based redundancy checks。
这些设计共同服务于一个目标:低成本地识别哪些子句不值得继续保留在搜索空间中。 饱和式证明器最怕的不是单步推理慢,而是搜索空间失控;冗余检测、单位等式重写和索引结构,本质上是在持续为证明过程“减重”。
6. Schedule 不是附属脚本,而是产品级能力
论文对“海量选项”采取了极其现实的态度。Vampire 的行为由 200 多个选项共同塑造,因此作者明确建议用户:不要迷信单次直跑,而应使用 portfolio mode 与 schedule。
推荐调用方式是:
vampire --mode portfolio --schedule <schedule> --cores 0 <problem>其背后的逻辑是,证明器的行为高度混沌,哪怕专家也很难凭经验为具体问题手工挑出最优策略。于是 Vampire 借助 Spider,从训练问题集中自动挑选彼此互补的策略,构造成覆盖率高、总运行时间短的 schedule,并进一步研究这些 schedule 对未见问题的泛化能力。
这说明一个常被忽略的事实:在今天的自动定理证明系统里,调度学习已经不是外围脚本,而是证明器产品化与可重复性能的重要组成部分。
示例的诊断意义:为什么论文选择“列表求和”
论文使用了一个表面上并不惊人的例子:证明“两个实数列表分别求和后相加,等于拼接后再求和”。但这个例子的诊断价值很高,因为它同时涉及:
- 代数数据类型(list);
- 递归定义函数(
sum); - 多态列表拼接;
- 实数算术;
- 结构归纳。
这不是为了炫耀某个 benchmark,而是在压缩版场景里展示 Vampire 的系统边界:验证问题的难点往往不在某一理论本身,而在多个理论边界同时出现。 论文借助这个例子表明,Vampire 当前能力的价值在于组合推理,而不仅仅是在某条单一基准线上提升成绩。
可迁移的系统设计原则
综合全文,可以把论文凝练成几条可迁移的设计原则:
| 系统原则 | 论文中的具体体现 | 实际意义 |
|---|---|---|
| 保留核心证明范式 | 仍以 superposition / saturation 为中心 | 能力扩展不至于破坏系统统一性 |
| 外部求解器按边界接入 | AVATAR + SAT/SMT、可选 Z3 | 把 ground reasoning 委派出去,但不让外部工具吞掉主循环 |
| 复杂能力先在 branch 演化 | HOL、递归综合先在 branch 上持续发展 | 降低对主线代码库的扰动,控制合并成本 |
| 策略依赖 schedule 而非人工拍脑袋 | portfolio mode、Spider 自动发现互补策略 | 用数据驱动调度来对抗搜索行为的混沌性 |
| 开源改变系统生命力 | BSD 开源后团队、用户与贡献者扩张 | 证明器不只是算法,也是一种长期维护的研究基础设施 |
尤其值得注意的是“branch 先行”这条。论文相当坦率地承认,高阶逻辑之类的扩展会对主代码库造成剧烈影响,因此采用分支长期共演、周期性同步主线的方式来控制风险。这种工程策略非常像大型基础设施项目,而不像传统意义上的“一次性论文原型”。
相关系统比较:Vampire 的边界到底在哪里
如果只看功能名词,Vampire、Z3、cvc5、E prover、Leo-III 很容易被混成一类“自动推理器”。但从系统边界看,它们其实代表了几条不同路线。下面这张表,适合把论文里隐含的比较关系一次性看清。
| 系统 | 核心范式 | 最擅长的问题类型 | 与 Vampire 最关键的边界 |
|---|---|---|---|
| Vampire | 饱和式一阶 ATP,以 superposition / saturation 为核心,并吸收 theories、induction、AVATAR、SAT/SMT 委派 | 含量词、一阶结构、归纳、组合理论、验证友好逻辑表达的问题;尤其适合“多个边界同时出现”的组合推理 | 它的独特处不在于某一单项最强,而在于把量词推理保留在主循环内部,同时按边界接入 SAT/SMT 与调度学习 |
| Z3 | SMT solver | 量化较弱或以quantifier-free / theory-heavy 为主的验证约束;位向量、数组、线性算术、Horn clauses、程序分析管线 | Z3 更像“理论求解基础设施”。它在 ground / theory reasoning 上通常更直接,但不是以饱和式量词搜索和归纳整合为主场 |
| cvc5 | SMT solver(广泛支持 SMT-LIB 理论,并在量词、SyGuS、字符串、数据类型等方面很强) | 工业与研究中的 SMT 工作负载;字符串、数据类型、约束求解、语法制导综合等 | 与 Z3 类似,cvc5 的核心优势在SMT 生态和理论覆盖;它可处理量词,但主要仍站在 SMT 传统上,而不是 Vampire 这种一阶 ATP 主循环范式 |
| E prover | 经典一阶饱和式 ATP,高度优化的 superposition / term ordering / strategy engineering | 纯粹或偏纯粹的一阶定理证明、TPTP 风格 ATP 竞赛问题 | E prover 与 Vampire 最近,但更像“把一阶饱和式 ATP 做到极致”的路线;相比之下,Vampire 更强调verification-oriented theories、induction 与跨层协作 |
| Leo-III | 高阶 ATP,面向 classical HOL / extensional type theory | 原生高阶逻辑推理、HOL 证明任务、相关高阶自动化场景 | Leo-III 的主场是 HOL;Vampire 虽有 HOL branch,但整体定位仍不是“以高阶逻辑为唯一中心”,而是以验证导向的一阶 + theories + induction 平台化整合为重点 |
如果把这五个系统压缩成一句话区分,可以这样理解:
- Z3 / cvc5:更像“理论求解器”和验证约束后端;
- E prover:更像“纯一阶 ATP 性能机器”;
- Leo-III:更像“原生 HOL ATP”;
- Vampire:则站在中间地带,试图把量词、一阶饱和搜索、理论扩展、归纳和外部协作组织成统一平台。
再换一种更工程化的看法
如果你面对的是不同类型的问题,可以粗略这样选:
| 问题画像 | 更自然的首选 | 原因 |
|---|---|---|
| 量化不多,但位向量、数组、字符串、线性算术很重 | Z3 / cvc5 | 这是 SMT 求解器最成熟的主战场 |
| 纯一阶逻辑证明,目标是尽可能强的 ATP 性能 | E prover / Vampire | 都属于饱和式 ATP 路线,但 E prover 往往更“纯 ATP” |
| 同时有量词、归纳、数据类型、算术、验证风格表达 | Vampire | 这是论文想证明 Vampire 正在变强的核心场景 |
| 原生高阶逻辑任务、本体就是 HOL 证明 | Leo-III | 高阶逻辑是它的主场,而不是附带扩展 |
| 既想利用 SAT/SMT,又不想放弃一阶量词主循环 | Vampire | 它的特点正是把 SAT/SMT 当协作层,而不是主导层 |
这张比较表真正想澄清的,不是谁“更强”,而是谁在哪一段推理责任链上更强。Vampire 的论文价值,恰恰在于它没有试图把自己伪装成另一个 Z3,也没有满足于做另一个 E prover;它要证明的是:一阶饱和式 ATP 也可以通过清晰的边界分工,长成面向软件验证的统一推理平台。
局限性与边界
这篇论文写得相当克制,局限性并没有被掩盖。
- 很多强能力仍需精细调度:200+ 选项意味着系统很强,也意味着默认配置并不总是最优。
- 高阶逻辑仍在 branch 中演进:说明 HOL 虽然重要,但与主线融合的代价依然很高。
- 非线性算术仍需部分外援或近似处理:Vampire 对复杂 theory reasoning 的支持尚未完全闭环。
- 它不是纯 SMT 求解器的替代品:在一些 theory-heavy 场景里,专门的 SMT 工具仍然更直接;Vampire 的优势在于量词、归纳和更复杂的一阶结构。
因此,对本文最准确的理解不是“Vampire 已经包打天下”,而是:Vampire 正在证明,饱和式 ATP 可以在不放弃自身传统优势的前提下,进入过去更像 SMT 或证明助手接口层的问题域。
结论:Vampire 的系统命题
《The Vampire Diary》的价值,不在于宣布某项全新理论,而在于它系统性地展示了一条可持续的演化路径:
- 以 superposition 为稳定内核;
- 用 ALASCA、归纳和多态逻辑扩展表达与推理边界;
- 用 AVATAR 把 SAT/SMT 融入整体架构;
- 用索引、冗余消除和 schedule 把工程成本控制住;
- 用开源与分支机制维护长期演化能力。
从这个角度看,Vampire 已经不仅是“强大的 ATP 工具”,而更接近一个面向软件验证的统一推理平台。它与证明助手、SMT 求解器、程序综合和反例构造的边界并没有消失,但这些边界正在被重新组织:不是谁替代谁,而是谁负责哪一段推理责任。
对自动推理系统设计者而言,本文最重要的启示是:系统竞争力越来越少来自单条 inference rule 的局部胜负,越来越多来自理论扩展、外部协作、调度学习与工程隔离的整体设计。 这正是 CAV / IJCAR 意义上的系统论文价值所在。