TraceAegis: 用溯源分析守护 Agent —— 层次化行为异常检测的实践
TraceAegis: Securing LLM-Based Agents via Hierarchical and Behavioral Anomaly Detection
Agent 安全的重点正从模型层面的对齐训练,转向对执行轨迹的实时监控。TraceAegis 的核心思路来自软件系统安全:把 Agent 的工具调用序列视为一个程序,从中提取层次结构约束和行为规则,在运行时检测偏离。这种方法不依赖对 LLM 本身的修改,也不需要预先定义详尽的规则。
论文概览
arXiv: 2510.11203
作者: Jiahao Liu, Bonan Ruan 等(新加坡国立大学 & 蚂蚁集团)
主题: Agent 执行轨迹异常检测、层次结构分析、行为约束建模
我觉得这篇论文的切入角度很务实。它没有试图去"修"大模型本身,而是把 Agent 视为一个软件系统——工具调用序列就是程序的执行路径,异常行为就是路径偏离。从这个角度看,软件工程中积累了几十年的程序分析经验,可以直接拿来用。
核心问题:规则难穷尽,单步检查不够
现有的 Agent 安全方案大致分两类:
-
模型中心方法:微调或对齐训练,让 LLM 本身更"安全"。问题是,安全训练无法覆盖所有 Agent 交互场景,而且 helpfulness 和 safety 的张力很难调和。
-
外部执行机制:预定义特定规则,在运行时检查。比如"不允许向外部地址发送邮件"。问题在于规则穷举困难、维护成本高,且容易出现漏报。
TraceAegis 走的是第三条路:不预设规则,从正常执行轨迹中自动学习行为模型,然后用这个模型检测异常。 这种思路和软件系统安全中的基于溯源(provenance)的分析一脉相承。
方法论
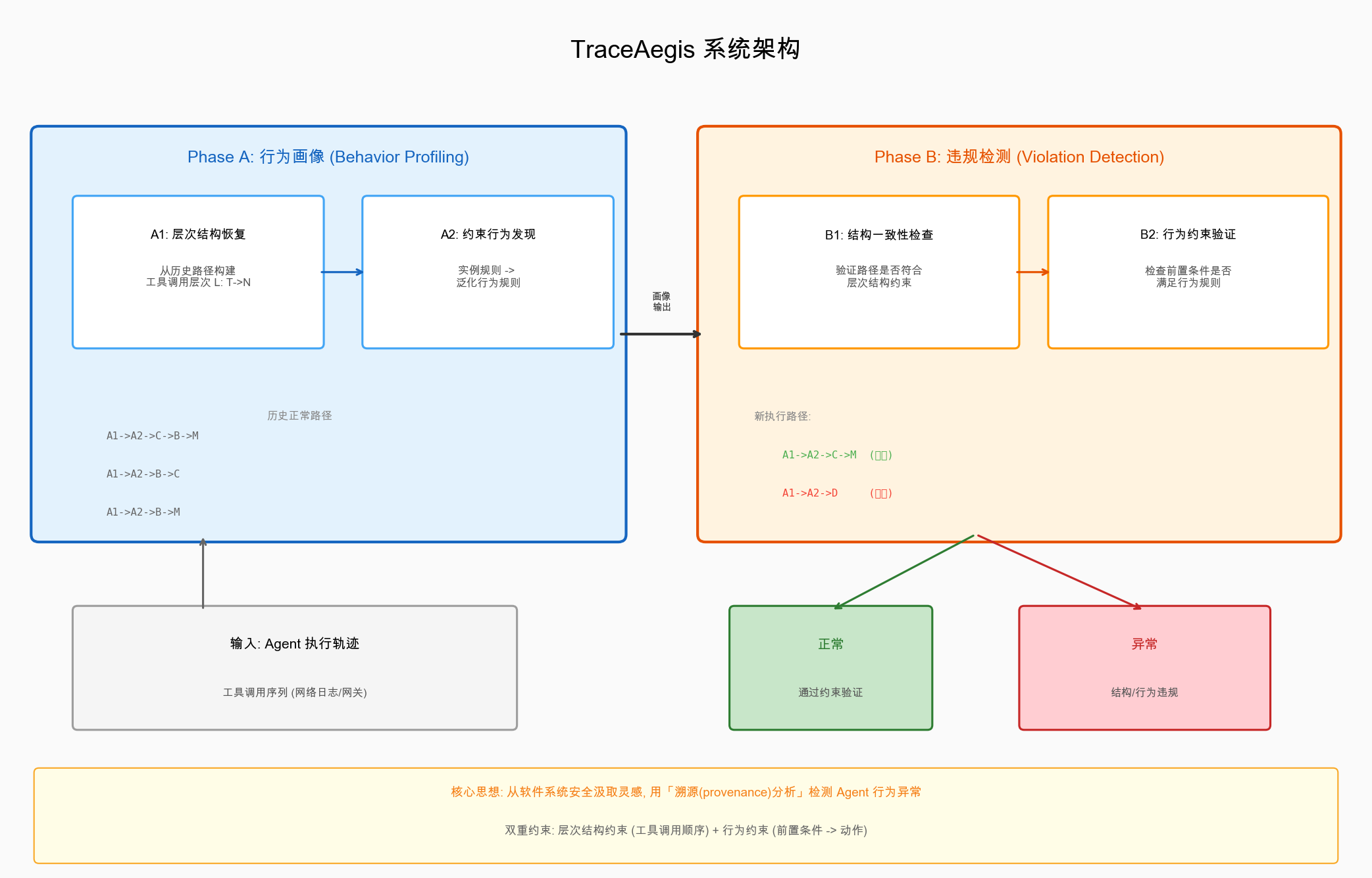
TraceAegis 分为两个阶段:
阶段 A:行为画像(Behavior Profiling)
给定一组历史的正常 Agent 执行路径(从网络日志/网关中提取的工具调用序列),TraceAegis 做两件事:
1. 层次结构恢复(Hierarchical Structure Recovery)
把工具调用序列组织成一个层次结构——一个 level mapping ,其中 是工具集合, 是工具 所在的层次。这个结构满足严格的性质:
- Property 1(严格层级):一个工具只能直接影响紧邻下一层的工具
- Property 2(内聚性):同一层的工具之间没有直接调用关系
- Property 3(完备性):每条正常路径都能被这个层次结构解释
这个结构是增量式构建的——每遇到一条新的正常路径,就更新相关节点的层级,并将变更传播到已有结构中。
2. 约束行为发现(Constrained Behavior Discovery)
层次结构提供了粗粒度的拓扑约束,但还不足以捕捉细粒度的行为语义。TraceAegis 进一步将路径分解为最小执行单元,然后为每个单元提取行为规则:
其中 是前置条件(完成这个动作需要满足什么), 是动作本身(做了什么操作)。
多个结构相似的实例规则会被聚合为一条泛化行为规则(Generalized Behavioral Rule),形如:
"如果患者挂了骨科号(前置条件),则必须先完成分诊和挂号,再调用骨科 API(动作)"
阶段 B:违规检测(Violation Detection)
当一条新的执行路径到来时,TraceAegis 做两层检查:
- 结构一致性检查:路径中的工具调用顺序是否符合层次结构?如果出现从未见过的组合,标记为异常。
- 行为约束验证:每个执行单元的前置条件是否满足对应的泛化规则?如果不满足,标记为异常。
两层检查是级联式的——先做轻量的结构检查,再做精细的行为验证,兼顾效率和精度。
TraceAegis-Bench 评测基准
论文同时构建了 TraceAegis-Bench:
| 场景 | 正常样本 | 异常样本 | 异常类型 |
|---|---|---|---|
| 医疗健康(Healthcare) | 1,300 | 300 | 执行顺序违规 + 语义一致性违规 |
| 企业采购(Procurement) | 1,300 | 300 | 执行顺序违规 + 语义一致性违规 |
两类异常的设计思路很巧妙:
- AT-C1(执行顺序违规):改变工具调用的顺序(如把验证步骤延后),导致执行结果不完整或被篡改。
- AT-C2(语义一致性违规):保持调用顺序不变,但替换了工具的输入内容(如把合法 URL 替换为恶意脚本),破坏语义一致性。
实验结果
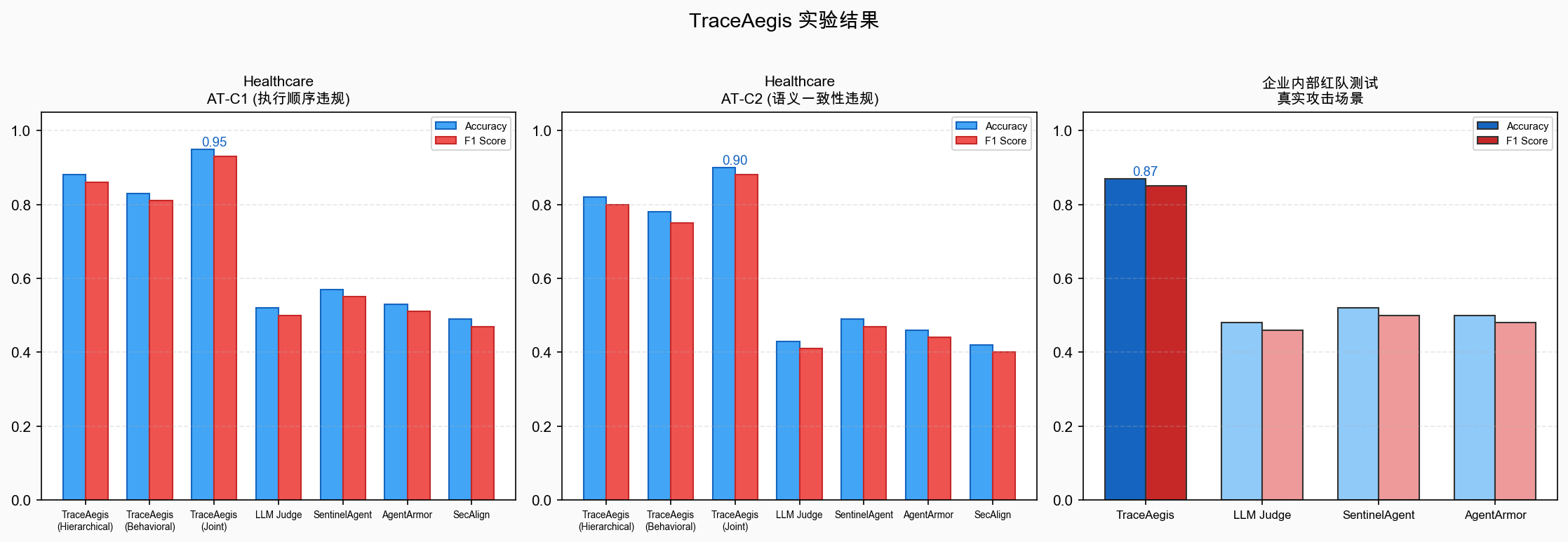
关键数据
在 Healthcare 场景上:
| 方法 | AT-C1 Accuracy | AT-C1 F1 | AT-C2 Accuracy | AT-C2 F1 |
|---|---|---|---|---|
| TraceAegis (Joint) | 0.95 | 0.93 | 0.90 | 0.88 |
| LLM Judge | 0.52 | 0.50 | 0.43 | 0.41 |
| SentinelAgent | 0.57 | 0.55 | 0.49 | 0.47 |
| AgentArmor | 0.53 | 0.51 | 0.46 | 0.44 |
| SecAlign | 0.49 | 0.47 | 0.42 | 0.40 |
TraceAegis 在两类异常上均大幅领先所有基线,Joint 检测在 AT-C1 上达到 95% 准确率。
企业内部红队验证
论文还报告了在蚂蚁集团内部进行的红队测试。TraceAegis 在真实攻击场景下达到 0.87 的准确率,而其他方法均不超过 0.52。
特别值得注意的是一个案例研究:攻击者通过 Code MCP 修改了代码仓库中的一个文件,将正常 URL 替换为恶意脚本,同时调整了工具执行顺序。这种攻击不包含任何显式的恶意载荷或可疑字符串,而是通过微妙的语义配置变化操纵跨步骤的执行依赖。传统基于内容或单步检查的方法完全无法检测,而 TraceAegis 通过重构层次结构和比对行为约束,成功识别了路径顺序违规和条件变更。
启示与思考
TraceAegis 让我看到了 Agent 安全研究的一个有价值的新方向。
从"修模型"到"看轨迹":目前绝大多数 Agent 安全研究都在模型层面做文章——要么改训练,要么改对齐,要么加护栏。但 TraceAegis 证明了,即使不碰模型本身,仅通过分析执行轨迹就能检测出绝大多数异常。这种"黑盒"式的防御天然更通用、更可迁移——换一个模型不用重新训练。
"正常行为"比"异常规则"更值得建模:预设异常规则的做法存在根本性的穷举困难——攻击者总能找到你没覆盖到的角落。而 TraceAegis 反其道而行之:建模正常行为,然后检测偏离。这和传统安全中的异常入侵检测系统(IDS)思路一致,但 TraceAegis 的创新在于用层次结构 + 行为规则两种约束,实现了比单一异常检测更精确的刻画。
局限也很明显:TraceAegis 的行为画像依赖充足的正常执行轨迹来构建——冷启动问题(新部署的 Agent 没有历史路径)可能严重影响效果。论文没有讨论这一点。此外,攻击者如果能在画像阶段注入伪装的正常路径(污染训练数据),可能会直接绕过整个检测框架。这种对抗场景在论文中也没有涉及。
从更宏观的视角看,我觉得 TraceAegis 代表了一种工程化的安全思路——不是追求理论上的完美防御,而是在现实约束下找到一个足够好的解。对于正在快速落地的 Agent 产品来说,这种思路的实用价值可能远大于"换一个更安全的大模型"。