SpecFS:把文件系统从“写代码”变成“写规范”
Sharpen the Spec, Cut the Code: A Case for Generative File System with SYSSPEC
这篇 FAST 2026 最佳论文提出了一个很大胆、也很克制的主张:与其让 LLM 直接从模糊提示词里“猜”出文件系统,不如先把功能、模块边界和并发协议写成结构化规范,再让模型负责生成实现。作者用 SYSSPEC 生成了 45 个模块、约 4300 行 C 代码的 SpecFS,并把 AtomFS 模块生成准确率推到 100%,还能用 DAG 化 spec patch 无缝接入 10 个 Ext4 特性。
一句话总结
这篇论文真正锋利的地方,不是“让大模型会写文件系统”,而是把问题倒过来:别再逼模型凭感觉写系统代码,而要先把系统的约束写清楚,再让它在约束里工作。
论文信息
- 机构:上海交通大学并行与分布式系统研究所
- 会议:USENIX FAST 2026
- 荣誉:Best Paper、Distinguished Artifact Award
- 原文:arXiv 2512.13047
- 项目页:llmnativeos.github.io/specfs
背景:文件系统最贵的,往往不是“新功能”,而是后面的长尾
我觉得这篇论文一上来最聪明的动作,不是谈 LLM,而是先谈 Ext4 这二十年的演化史。作者统计了从 Linux 2.6.19 到 6.15 的 3157 个 Ext4 提交,结果相当刺眼:82.4% 的提交都花在 bug 修复和维护上,真正新增功能只占 5.1%。更有意思的是,fast commit 这个功能最初实现只用了 9 个提交,后面却又拖出了 约 80 个后续提交来修修补补。
这件事很像我们熟悉的软件现实:一个功能写出来,并不意味着它真的“完成”了;它只意味着你刚刚为未来几年制造了新的责任。文件系统尤其如此。它既要处理状态一致性,又要处理模块依赖,还要处理锁、并发、路径遍历、inode 约束这些脾气古怪的细节。于是,所谓“新增一个特性”,在工程上常常不是加一段代码,而是轻轻碰一下某个数据结构,整个系统就跟着抖三抖。
所以作者提出的“生成式文件系统”(generative file system)并不是一句炫技口号。它针对的是一个很具体的矛盾:既然文件系统的主要痛苦在于演化,那我们就不该只让 LLM 帮忙生成第一次代码,而应该让它参与整个“规范—实现—演化”的闭环。
核心创新:不是更长的 prompt,而是更像样的 specification
SYSSPEC 的核心主张,可以压缩成一个简单写法:
其中:
- :Functionality,用前置条件、后置条件、不变量和算法意图描述“函数要做什么”;
- :Modularity,用 Rely/Guarantee 合约描述“模块如何组合”;
- :Concurrency,把锁协议与顺序关系显式写出来,描述“并发下什么是合法行为”。
论文最重要的判断是:自然语言 prompt 之所以在系统软件里失灵,不是模型不够聪明,而是任务本身太依赖边界、约束和局部推理。你让模型“写一个文件系统”,它当然会像一个见多识广但记性不稳的实习生,写出看着像那么回事的东西;可一旦碰到锁顺序、接口兼容、跨模块变更传播,它就很容易露出破绽。
SYSSPEC 解决这个问题的方式,不是堆更多提示词,而是把规格拆成三层:
- 功能规格:像弱化版 Hoare Logic,用结构化自然语言写清状态转移;
- 模块规格:用 Rely/Guarantee 约束依赖接口,避免“这个模块以为别人会返回 A,另一个模块其实只保证 B”;
- 并发规格:把锁的拥有关系、释放条件、顺序依赖单独拎出来,不让它和业务逻辑混成一锅粥。
这其实很像写文章时先列提纲。提纲不是文章,但没有提纲,长文章就会散;规格不是程序,但没有规格,复杂系统就会漂。论文做的事,就是把这种朴素经验推进到了一个可以喂给 LLM 的工程层面。
方法论:把“生成实现”变成一个受约束的编译过程
论文把高层规格到低层实现的过程写成一种近似“编译”的关系:
这里 是规格, 是基于 LLM 的工具链,输出是可运行的 C 实现 ImpFS。当系统需要演化时,不直接改 C 代码,而是先写一个规格补丁:
我很喜欢这里的 DAG patch 设计。它很像在告诉开发者:不要手工在实现里追着依赖跑,而要在设计层面说清“这个变化会触发哪些模块重生”。 这比单纯“自动重构”更上游,因为它把演化的因果链收回到了 specification 层。
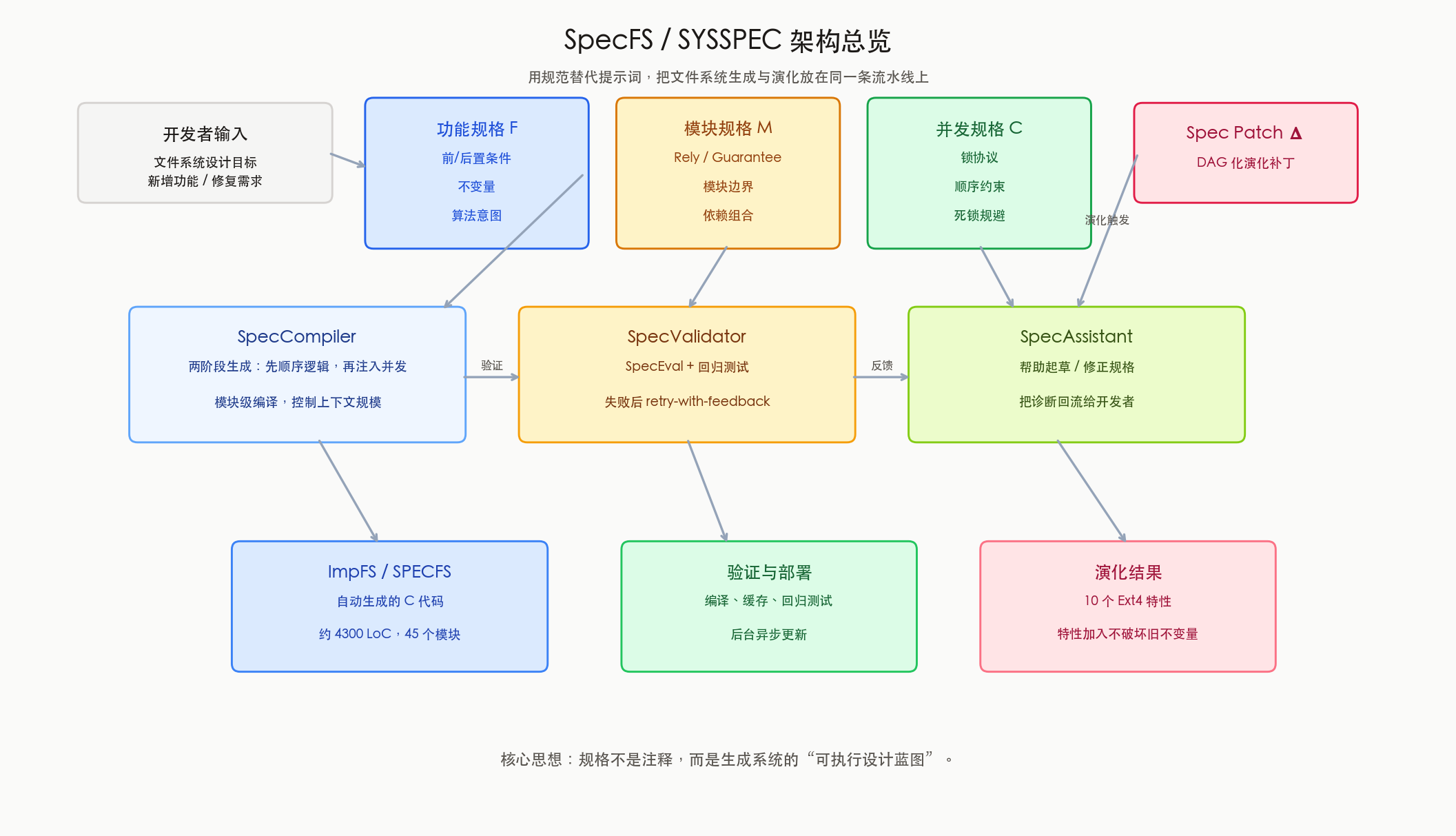
图:SYSSPEC 把开发者输入组织为三类规格,再通过 SpecCompiler、SpecValidator、SpecAssistant 三个 Agent 生成、校验、修正规格对应的实现。Spec patch 则负责高层演化。
具体来说,工具链由三个 Agent 组成:
1. SpecCompiler:先顺序,后并发
SpecCompiler 采用两阶段生成:先根据功能规格生成顺序版本,再依据并发规格给代码“装上锁”。这看起来像个小技巧,其实很关键。因为并发错误的本质往往不是算法错了,而是正确算法被错误的时序包裹了。先把逻辑骨架立稳,再加并发外壳,比一开始就把一切揉在一起靠谱得多。
2. SpecValidator:别迷信一次成功
作者并没有对 LLM 表现出不必要的信任。SpecValidator 会把生成结果再交给另一个推理流程审查,并结合回归测试做最终验证。这个 retry-with-feedback 环路很重要:它承认模型会犯错,但要求错误必须在规格边界内被反复逼近、纠正,而不是任其留在系统里等生产环境去发现。
3. SpecAssistant:帮助人把规格写得像规格
这个组件很有现实感。因为真正的瓶颈不只在“代码难写”,还在“好的规格也难写”。SpecAssistant 做的是 human-in-the-loop 的规格润色:检查格式、调用编译器试跑、把失败诊断再反馈给规格本身。换句话说,它不只是帮你写代码,还帮你学会如何描述系统。
如果要把这个流程压缩成伪代码,大概可以写成:
for module in topological_order(specification):
seq_impl = generate_from_functionality(module)
conc_impl = inject_concurrency(seq_impl, module)
while not validate(conc_impl, module):
conc_impl = retry_with_feedback(conc_impl)而模块之间的拼接,依赖的是一个非常朴素但有力的关系:
也就是:上游模块真正承诺的东西,必须能满足下游模块的依赖假设。把这个关系写清楚,模块组合才不会靠运气。
实验结果:它不是“看上去能跑”,而是真的做出了几件硬事
作者用 SYSSPEC 生成了 SPECFS:一个 FUSE 用户态文件系统,包含 45 个模块、约 4300 行 C 代码,支持 open、read、rename 等一系列 POSIX 接口。它在 xfstests 中 754 个测试里只失败 64 个,且失败原因都来自尚未实现的功能,而不是逻辑偏差。这已经说明它不是一个演示性质的玩具。
更有分量的是几组量化结果:
| 结果 | 数值 | 含义 |
|---|---|---|
| AtomFS 45 模块生成准确率 | 100% | Gemini-2.5-Pro、DeepSeek-V3.1 上全部生成正确 |
| 最强 oracle baseline | 81.8% | 即便把依赖代码也塞进 prompt,仍显著落后 |
| 正确率增益 | 最高 34.4% | 相比朴素 prompting 的复杂操作生成 |
| 线程安全模块消融 | 0% → 80% → 100% | 加入并发规格和验证器后才真正站稳 |
| Extent 开发效率 | 1.5h vs 4.5h | 约 3.0× 提升 |
| Rename 开发效率 | 2.4h vs 13h | 约 5.4× 提升 |
| Delayed Allocation 效果 | 最高减少 99.9% 写操作 | 在 I/O 密集任务中收益显著 |
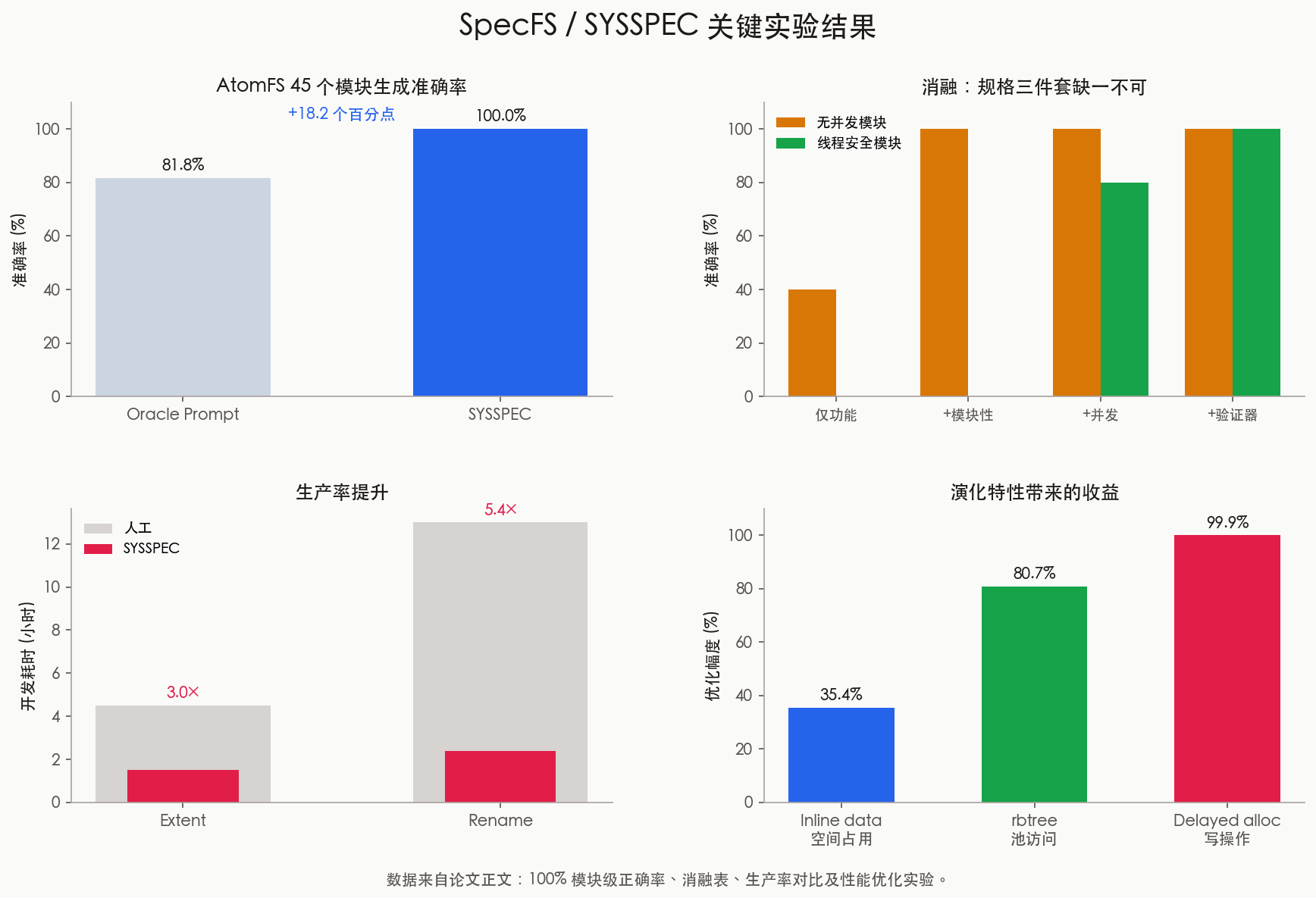
图:论文中的关键结果可以压缩成四句话:规格优于 prompt、模块性和并发性缺一不可、复杂功能开发更快、演化后的性能收益是真实可测的。
我尤其看重它的消融实验。只有功能规格时,40 个无并发模块只有 40% 正确率;加入模块规格后,无并发模块直接到 100%;但 5 个线程安全模块 仍然是 0%。直到显式引入并发规格,准确率才到 80%;再加验证器,才变成 100%。这组数据几乎是在用实验复述一个工程常识:并发不是“顺序程序 + 几把锁”,而是一层独立设计。
性能实验也不是纸上谈兵。作者演示了 10 个来自 Ext4 的真实特性:比如 Inline Data 让 QEMU 和 Linux 源码场景的空间占用分别下降 35.4% 和 21.0%;rbtree for Pre-Allocation 在 20MB 文件、1000 次写入时可把块池访问次数降低 80.7%;Delayed Allocation 则在某些工作负载里把写操作几乎清零。
启示与思考:这篇论文真正想生成的,也许不是文件系统,而是一种新的工程分工
我读完以后最大的感受是:这篇论文不是在证明“LLM 可以替代系统程序员”,而是在重新划分“人负责什么,模型负责什么”。
过去我们总把代码生成理解成一种自动化写作:人提需求,模型吐实现。可对文件系统这种东西来说,真正昂贵的不是把 C 语法写出来,而是把约束想明白、把接口边界划清楚、把并发条件说明白。SYSSPEC 的妙处就在于,它把人的工作重新抬高到“写 specification”,把模型的工作限制在“根据 specification 编译实现”。这比“万能 prompt 工程”诚实得多,也可能现实得多。
当然,它还远没有抵达终点。论文自己也承认,当前 SPECFS 基于 FUSE,没有进入内核态,也没有处理 crash consistency,因此不能和原生内核文件系统做严格的吞吐对比。另一个限制是:如果你真要用这套方法去生成 Ext4 那样的工业级系统,规格本身会变成新的复杂对象。也就是说,复杂度并没有消失,只是从代码迁移到了规格。
但我反而觉得,这正是它最值得认真对待的地方。复杂度不可能被魔法消灭;能做的,只是把复杂度放在更容易审查、更容易组合、更容易演化的位置上。代码很难同时满足这三个条件,而 specification 也许可以。若再往前一步,把 SYSSPEC 和 push-button verification 真正接起来,那时“生成式系统”才会从今天的实验味道,慢慢长出一点工业气息。
说到底,这篇 FAST 最佳论文让我相信一件事:未来的系统软件开发,也许不是“少写设计文档,多写代码”,而恰恰相反。 代码会越来越像一种可再生资源;真正稀缺的,是写出足够清晰、足够强硬、又足够可演化的设计约束的能力。
参考资源
标签:#AI解读 #文件系统 #操作系统 #LLMAgent #形式化方法