用一个 Agent 守护另一个 Agent:ShieldAgent 的形式化安全防护
ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning
当 LLM Agent 在网页购物、股票交易、代码执行中穿行,谁来保证它们不越界?ShieldAgent 的答案是:再造一个 Agent 来专门「盯着」它——用概率规则电路做形式化验证,而不是凭感觉拒绝。这比简单的提示词护栏强在哪?本文带你拆解它的架构与数据。
论文概览
arXiv: 2503.22738 | ICML 2025
作者: Zhaorun Chen、Mintong Kang、Bo Li(芝加哥大学 & UIUC)
项目主页: shieldagent-aiguard.github.io
这篇论文解决的是一个被大多数人忽视的问题:我们花了大量精力让 LLM 本身「对齐」,但当它被套进一个具备工具调用能力的 Agent 框架后,安全性的保证就瞬间碎片化了。提示词注入、记忆投毒、环境操控——任何一条攻击路径都可能让一个「安全」的模型执行出危险的操作序列。
ShieldAgent 的核心主张是:不要试图用一个 LLM 的直觉来判断另一个 LLM 的行为是否安全,而是把安全策略形式化成可验证的逻辑规则,然后用形式化工具来核对轨迹。这是一种从「经验主义」到「形式主义」的转变,在 Agent 安全领域相当少见。
核心创新
1. 动作语义策略模型(ASPM)
ShieldAgent 不直接用 LLM 判断行为是否违规,而是先把安全策略文档(比如 GitLab 使用手册、电商平台条款)转化成一套结构化的逻辑规则系统。
每一条规则被建模为 动作语义概率电路(Action-based Probabilistic Circuit),形如:
这是有限线性时序逻辑(LTL_f)的语法。用时序逻辑来表示 Agent 行为轨迹,允许表达「某个动作之前必须满足某个条件」「在轨迹的某个时间点内必须执行某步」这类跨步骤约束。
相比直接让 LLM 回答「这个轨迹是否违规」,形式化规则电路的优势在于:可解释、可复用、可验证,同时大幅减少对闭源 API 的调用次数。
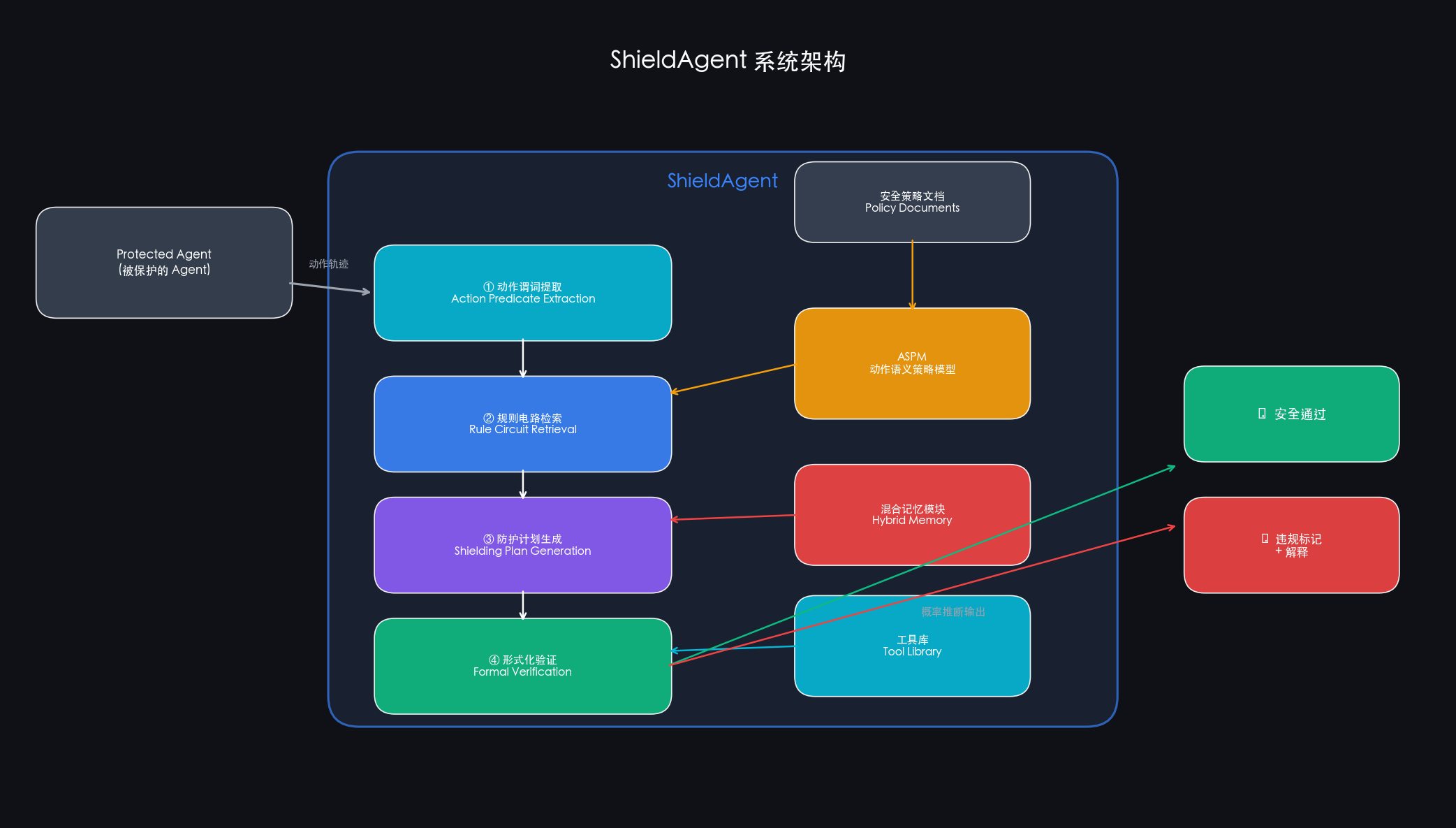
2. 实时防护流程(Shielding Pipeline)
给定一个被保护 Agent 的动作轨迹,ShieldAgent 每一步都做以下事情:
- 动作谓词提取:从 Agent 的输出中解析出语义谓词(如
AccessPage(url),SubmitForm(data)) - 规则检索:从 ASPM 中取出与当前动作相关的规则电路
- 防护计划生成:基于长期记忆中的历史成功工作流,用 few-shot 生成验证步骤
- 形式化验证:调用 model-checking 工具(Stormpy 等)对谓词真值赋值并验证规则
- 概率推断:对验证结果做概率聚合,输出最终安全标签 + 解释
这四个操作分别对应四种「防护动作」类型:Search(枚举)、Binary-Check(二分类)、Detect(调用内容审核 API)、Formal Verify(形式验证)。
3. ShieldAgent-Bench:首个综合型 Agent 防护基准
论文同时发布了迄今为止规模最大、维度最全的 Agent 防护评测基准:
| 基准 | 样本数 | 风险类别 | 攻击类型 | 环境数 | 规则注解 |
|---|---|---|---|---|---|
| ST-Web | 234 | 3 | 0 | 3 | 36 |
| AgentHarm | 440 | 1 | 0 | 0 | 0 |
| VWA-Adv | 200 | 1 | 1 | 3 | 0 |
| ShieldAgent-Bench | 3,110 | 7 | 2 | 6 | 1,080 |
七类风险涵盖:访问限制、内容限制、幻觉、指令遵从、操作风险、错误处理、长期一致性。两类攻击分别针对 Agent 内部(AgentPoison:记忆投毒)和外部环境(AdvWeb:页面内容篡改)。
方法论深度解析
ASPM 结构优化
原始从策略文档中提取的规则往往存在两个问题:模糊性(同一概念多种表达)和冗余性(重复规则)。ShieldAgent 设计了迭代优化流程,最多进行 10 轮精化:
以 Shopping 环境为例,优化前有 920 个谓词、562 条规则,平均模糊度 0.71;优化后压缩到 461 个谓词、240 条规则,模糊度降至 0.38。这种压缩不只是「量变」,它直接影响推理效率和验证精确度。
混合记忆模块
ShieldAgent 设计了两层记忆:
- 短期记忆(KV-cache):缓存当前轮次的 Agent-环境交互,验证完成即清空,避免上下文膨胀
- 长期记忆(成功工作流库):把验证成功的流程存储下来,下次遇到类似动作直接复用,不必重新规划
这个设计在实测中带来了显著的效率提升:API 调用减少 64.7%,推理时间压缩 58.2%。
实验结果
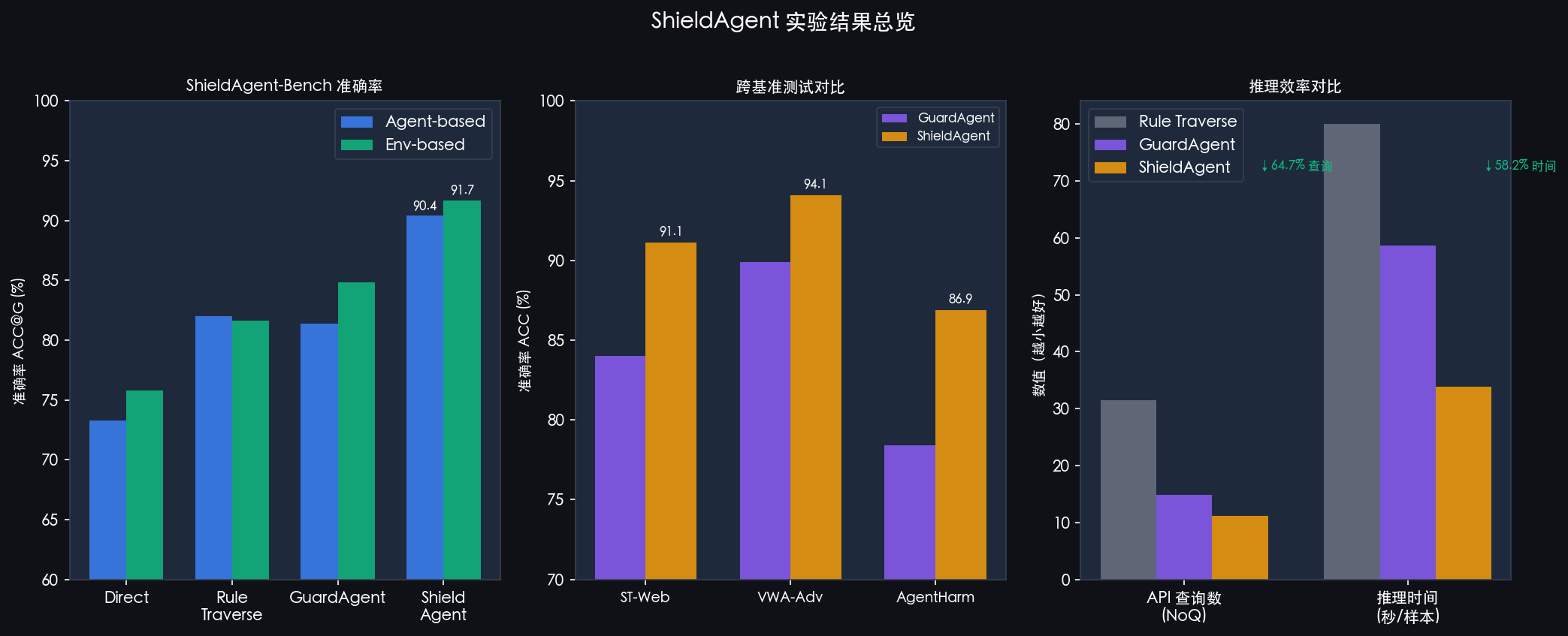
ShieldAgent-Bench 主实验
在两种攻击类型(Agent-based / Environment-based)下:
| 方法 | ACC@G (Agent) | ACC@G (Env) | FPR@G | ARR@R | NoQ | Time(s) |
|---|---|---|---|---|---|---|
| Direct | 73.3 | 75.8 | 7.1 | 31.5 | 1 | 6.5 |
| Rule Traverse | 82.0 | 81.6 | 16.6 | 72.0 | 29.3 | 77.7 |
| GuardAgent | 81.4 | 84.8 | 12.5 | 62.9 | 14.2 | 60.5 |
| ShieldAgent | 90.4 | 91.7 | 4.8 | 90.1 | 10.4 | 32.5 |
ShieldAgent 在准确率上比最强 baseline 高 10.2%,同时误报率最低(4.8%),规则召回率高达 90.1%,且效率最优。
跨基准泛化
在三个独立基准(ST-WebAgentBench、VWA-Adv、AgentHarm)上,ShieldAgent 平均超越第二名 7.4%,在 ST-Web 上的 Consent 和 Boundary 两类风险上提升尤为显著。
启示与思考
我觉得这篇论文最值得关注的,不是那几个百分点的提升,而是它提出的范式转变——从「用模型感知安全」到「用形式化逻辑验证安全」。
这种思路在传统软件工程中其实早就存在:我们用类型系统、契约(contract)、运行时断言来保证程序行为,而不是靠程序员的直觉。把这套哲学迁移到 Agent 安全领域,逻辑上是成立的,工程上也是可行的——ShieldAgent 用实验证明了这一点。
当然,局限也很明显:当前的 ASPM 依赖预先存在的策略文档,对于动态、开放的任务域(比如用户完全自定义的 Agent 工作流)还无法直接适用;幻觉类风险的准确率也相对偏低,因为这类违规需要外部知识来裁定,超出了策略文档的覆盖范围。
从更宏观的视角看,随着 OpenAI Operator、Anthropic Computer Use 这类「真正帮你操作电脑」的 Agent 逐渐进入日常使用,ShieldAgent 这类「守护者 Agent」或许会成为 Agent 基础设施中不可缺少的一层。一个 Agent 生态里,可能需要的不只是功能 Agent,还需要专职的安全 Agent 24 小时盯着它们的轨迹。