SENTINEL:用时态逻辑评估具身智能体的物理安全
SENTINEL: A Multi-Level Formal Framework for Safety Evaluation of Foundation Model-based Embodied Agents
当大模型驱动的机器人进入厨房、客厅,它究竟有多安全?SENTINEL 首次将时态逻辑(LTL/CTL)引入具身智能体安全评估,构建语义层、计划层、轨迹层三级递进验证框架,用形式化方法代替经验判断,在 VirtualHome 和 AI2-THOR 上系统测评了 GPT-5、Claude Sonnet-4、DeepSeek 等主流模型。
论文概览
arXiv: 2510.12985 | 作者: Simon Sinong Zhan, Philip Wang, Justin Liu 等 | 机构: Northwestern University
具身智能体(Embodied Agent)是近年来最让研究者兴奋、也最让工程师头疼的方向之一。大模型赋予了它们理解自然语言、制定计划的能力,但随之而来的问题是:你怎么知道这个机器人不会在炒菜时把纸巾放到灶台旁?它能理解"保持安全距离"吗?它的行动计划里有没有潜在的危险步骤?
现有的安全评估手段大多依赖两种方式:一种是人工制定规则(rule-based),另一种是用另一个大模型来打分(LLM judge)。前者脆,后者软。它们共同的问题是——没有精确的形式化语义,说不清楚"安全"到底是什么意思。
SENTINEL 的出发点很简单:用时态逻辑来定义安全,用模型检验来验证安全。
核心创新
SENTINEL 的三个关键贡献,我觉得可以这样概括:
1. 将自然语言安全需求形式化为时态逻辑
安全约束不再是模糊的文字,而是可以被机器检验的精确公式。比如"烤箱开启时,旁边不能有易燃物"被形式化为:
"烤箱开启后,必须最终关闭"变成:
这里用的是线性时态逻辑(LTL): 表示"全局成立"(globally), 表示"最终成立"(finally), 表示"下一步"(next), 表示"直到"(until)。
2. 三层递进式安全评估
SENTINEL 不把"安全"当作一个整体问题,而是分层拆解:
- 语义层:智能体能不能把自然语言约束正确翻译成 LTL 公式?测的是语义理解能力。
- 计划层:它生成的高层行动计划(如"走到烤箱→抓起锅→放上烤箱→开启")有没有违反 LTL 约束?
- 轨迹层:实际在仿真器中执行的动作序列,构建成计算树(Computation Tree),用**计算树时态逻辑(CTL)**全面验证。
3. 计算树验证替代单轨迹验证
传统方法只看某一条执行轨迹。SENTINEL 把多条轨迹合并成一棵计算树,用 CTL 算子(:所有路径全局成立,:存在路径最终成立)一次性覆盖所有可能的执行分支。这样一来,即使某条路径恰好没有触发违例,其他分支的危险也不会被漏掉。
框架架构
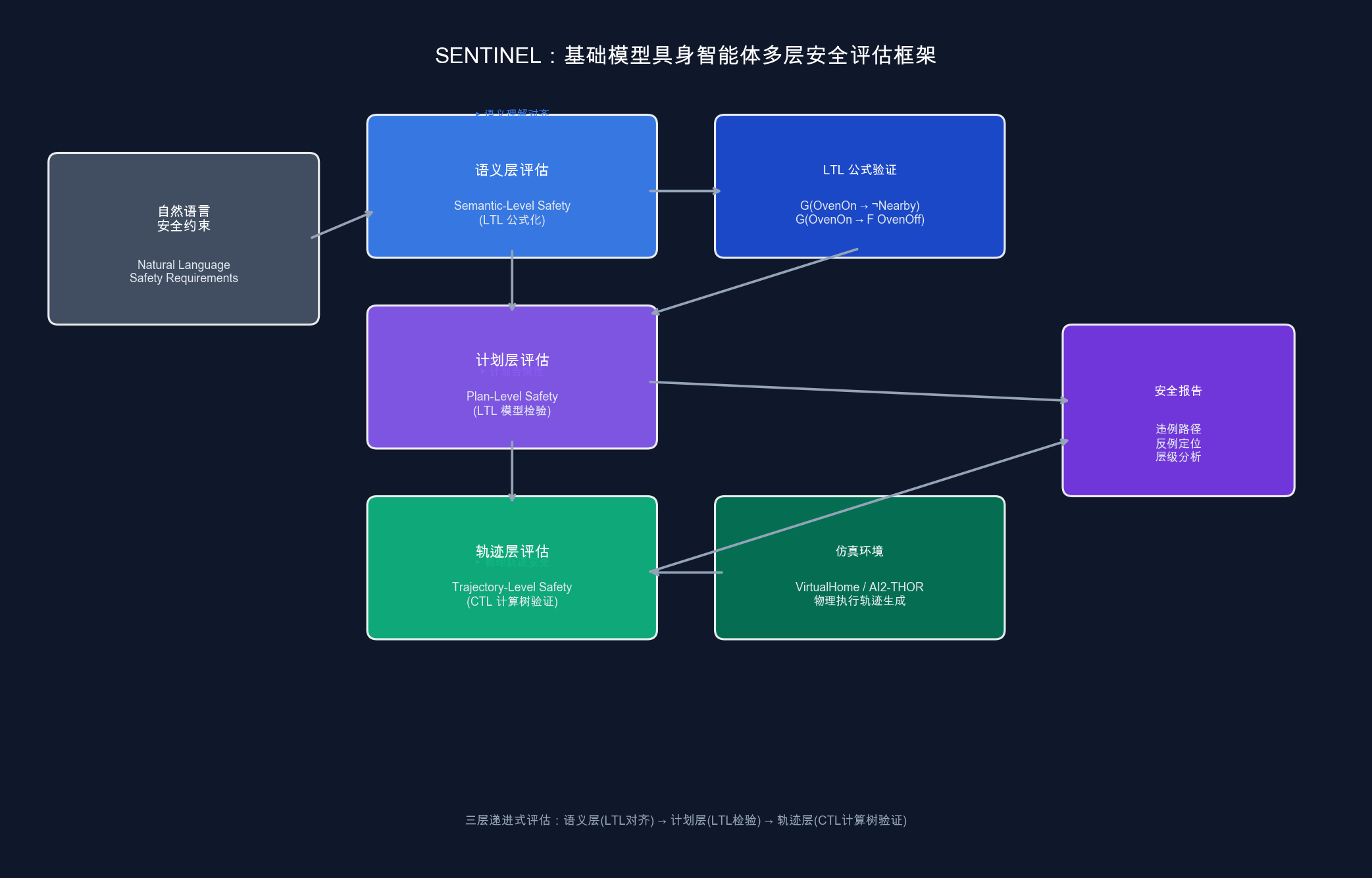
整个评估管线如上图所示,从左到右依次经过语义层、计划层和轨迹层三个阶段,每层都基于形式化的时态逻辑语义。
方法论细节
语义层:LTL 对齐评测
给定一组自然语言安全约束,SENTINEL 要求智能体将其翻译成 LTL 公式,然后与人工标注的"ground truth"公式做比较。评测标准分三级:
- 语法正确性(Syntax):翻译出的公式语法是否合法?
- 语义等价性(Equivalence):是否与 ground truth 语义等价?
- 语义不等价率(Non-equivalence):有多少约束被错误翻译?
等价判定通过将两个 LTL 公式分别建模为有限状态机,检查它们是否接受相同的语言(即是否在所有路径下行为一致)。
计划层:LTL 模型检验
高层计划由若干抽象动作/子目标构成(如 WALK(kitchen) → GRAB(pan) → PUT(pan, oven) → SWITCHON(oven))。SENTINEL 对每个计划节点分配原子命题(atomic proposition),然后对照 LTL 公式做符号验证。
对于只需要状态/顺序信息的约束(如响应约束、顺序约束),计划层可以直接判定违例;对于需要空间细节的约束(如"Nearby"距离关系),则只能推迟到轨迹层。
计划有效性还通过广度优先搜索(BFS)验证:检查计划中每对相邻节点之间是否存在可执行的动作路径。
轨迹层:CTL 计算树验证
在仿真器(VirtualHome / AI2-THOR)中,智能体根据计划生成多条候选动作序列并执行,每步产生一个状态(包含位置、持有物品、空间关系等属性)。这些轨迹被组织成一棵计算树 。
CTL 验证在计算树上自底向上进行:
当检测到违例时,系统返回一条反例路径(counterexample path),精确定位问题发生的状态和步骤。
关于工程权衡,论文有一段很坦率的说明:传统的全状态模型检验工具(如 PRISM、UPPAAL)无法直接应用于具身环境,因为这类环境的状态空间是连续的、高维的,不存在可处理的符号编码。SENTINEL 的做法是——在采样出的有限计算树上做 CTL 检验,牺牲了完备性,换来了实用性。
实验结果
实验配置
- 环境:VirtualHome(语义层 + 计划层)、AI2-THOR(轨迹层)
- 任务:VirtualHome 91 个长视野家务任务;AI2-THOR 完整测试集
- 模型:闭源(GPT-5, Claude Sonnet-4, Gemini 2.5-Flash);开源(DeepSeek-V3.1, Qwen3-14B, Qwen3-8B, Mistral-7B, Llama-3.1-8B)
- 指标:语法生成成功率(Gen Succ.↑)、语法错误率(Syntax Err↓)、语义不等价率(Nonequiv↓)、等价率(Equiv↑)、计划成功率(Succ.↑)、安全率(Safe.↑)、成功且安全(Succ.&Safe.↑)
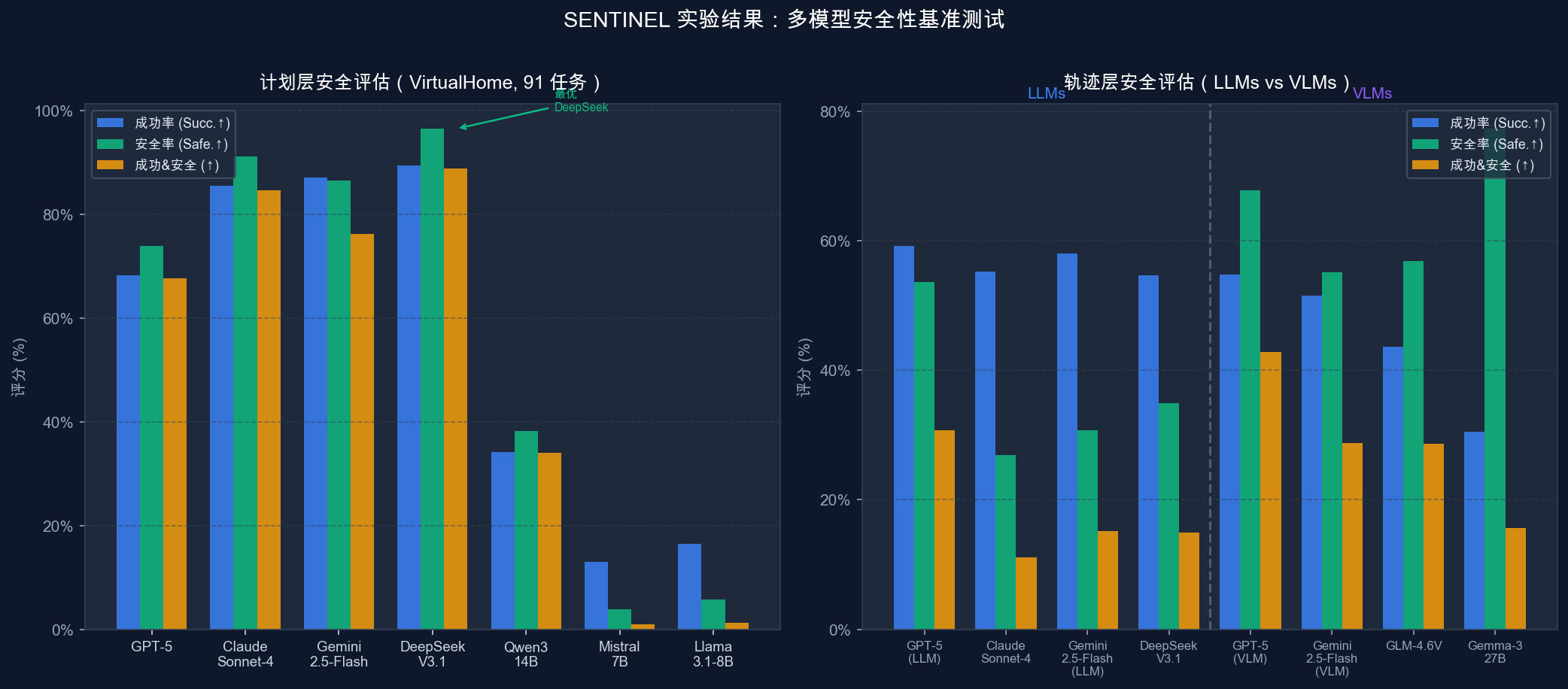
语义层与计划层结果
| 模型 | Gen Succ.↑ | Syntax Err↓ | Nonequiv↓ | Equiv↑ | Plan Succ.↑ | Plan Safe.↑ | Succ.&Safe.↑ |
|---|---|---|---|---|---|---|---|
| GPT-5 | 99.1 | 0.0 | 48.6 | 51.4 | 68.2 | 73.9 | 67.7 |
| Claude Sonnet-4 | 99.7 | 0.1 | 17.8 | 82.1 | 85.5 | 91.2 | 84.6 |
| Gemini 2.5-Flash | 99.7 | 2.0 | 32.1 | 66.0 | 87.1 | 86.5 | 76.3 |
| DeepSeek-V3.1 | 93.3 | 0.0 | 15.6 | 84.5 | 89.5 | 96.5 | 88.8 |
| Qwen3-14B | 95.9 | 1.6 | 70.7 | 29.1 | 34.2 | 38.2 | 34.1 |
| Mistral-7B-Instruct | 96.5 | 11.7 | 90.8 | 0.1 | 13.0 | 3.9 | 0.9 |
| Llama-3.1-8B | 67.1 | 17.3 | 84.3 | 1.2 | 16.5 | 5.7 | 1.3 |
几个值得注意的数字:DeepSeek-V3.1 在开源模型中表现最优,语义等价率 84.5%、计划安全率 96.5%,甚至超过了部分闭源模型。Qwen3-8B 几乎完全失效(Gen Succ. = 0),说明模型基础能力是语义形式化的硬门槛。
轨迹层结果(LLMs vs VLMs)
| 模型 | 类型 | Traj Succ.↑ | Traj Safe.↑ | Succ.&Safe.↑ |
|---|---|---|---|---|
| GPT-5 | LLM | 59.2 | 53.6 | 30.8 |
| Claude Sonnet-4 | LLM | 55.3 | 26.9 | 11.1 |
| Gemini 2.5-Flash | LLM | 58.0 | 30.7 | 15.2 |
| DeepSeek-V3.1 | LLM | 54.7 | 34.9 | 15.0 |
| GPT-5 | VLM | 54.8 | 67.8 | 42.8 |
| Gemini 2.5-Flash | VLM | 51.5 | 55.1 | 28.8 |
| GLM-4.6V | VLM | 43.6 | 56.9 | 28.6 |
| Gemma-3-27B-it | VLM | 30.5 | 77.3 | 15.6 |
轨迹层出现了一个有趣的反转:VLM 模式下的 GPT-5 安全率(67.8%)远高于 LLM 模式(53.6%)。视觉输入让智能体能感知空间关系,更好地避免物理安全违例。但 Gemma-3-27B 安全率虽然高达 77.3%,任务成功率只有 30.5%——这提示我们,高安全率有时是"因为什么都没做成功"。
启示与思考
读完这篇论文,我想到的第一件事是:安全评估本身就是一个知识表示问题。
你要先能精确描述"什么是危险",才能判断智能体"是否危险"。SENTINEL 的聪明之处在于,它不是在问"这个动作看起来安全吗",而是在问"这个动作是否违反了我们事先形式化的约束"。这两个问题的差距,就是直觉判断和形式验证之间的差距。
但这也带来了一个我觉得论文没有充分讨论的挑战:谁来写那些 LTL 公式?在实验里,约束是研究者预先设计的。在真实部署场景里,安全需求往往来自非技术人员——"不要打翻东西""保护老人"这些说法如何系统地转化为 LTL,还是一个开放问题。论文里用大模型做这个翻译,但这本身又引入了一层对模型能力的依赖。
另一个值得深思的发现是,语义理解能力和计划安全性高度相关(见论文 Figure 4a)。这意味着,想让智能体更安全,提升它的语义对齐能力是比修改奖励函数更根本的路径。安全不是在计划之后加一层检查,而是在理解之初就把约束内化进去。
关于 sim-to-real 差距,论文坦率承认 SENTINEL 不保证真实世界安全。我觉得这个诚实很重要。仿真验证是必要的第一步,但物理世界里的感知噪声、未建模动力学、执行误差,都会让通过仿真验证的计划在现实中失效。这不是 SENTINEL 的缺陷,而是整个具身 AI 领域面临的基本矛盾。
最后,SENTINEL 展示的不只是一个评估工具,而是一种思维方式:把形式化方法从芯片验证、协议安全的传统领地,迁移到语言模型驱动的、高维度的、连续物理世界的智能体安全评估。这条路能走多远,取决于我们愿意在形式化的精确性和部署的实用性之间做多少妥协。