Qualixar OS:AI Agent 编排的通用操作系统
Qualixar OS: A Universal Operating System for AI Agent Orchestration
首个为 AI Agent 编排构建的应用层操作系统,支持 12 种多 Agent 拓扑、10 个 LLM 提供商、8+ 框架,集成质量保障管道、成本路由和 24 标签页仪表板。
原始标题:Qualixar OS: A Universal Operating System for AI Agent Orchestration 作者:Varun Pratap Bhardwaj(独立研究者,Solution Architect,印度) 发表:arXiv 2604.06392,2026 原文:PDF 链接 | GitHub
论文概览
AI Agent 生态正在变得像 20 世纪 90 年代的编程语言战场——AutoGen、CrewAI、MetaGPT、LangGraph 各有一套 agent 定义、执行模型和工具链,一个框架里写的 agent 没法直接跑在另一个框架里。更要命的是,这些框架都不提供成本追踪、质量保证或者管理仪表板。
Qualixar OS 的核心论点是:AI Agent 生态需要的是一个操作系统,而不是又一个框架。就像 Linux 为应用程序提供通用运行时(不管用啥语言),agent OS 也应该为编排提供通用运行时(不管用啥框架)。这不是在底层做资源调度——那是 AIOS 在 COLM 2025 的工作。Qualixar OS 走的是应用层路线,专注于编排原语、用户体验和生态兼容性。
核心创新
- 12 种多 Agent 拓扑执行语义:从顺序链、DAG、网格到森林、Maker 模式,定义了最完整的开源拓扑集合
- Forge:LLM 驱动的团队设计引擎:根据自然语言任务描述自动生成完整的 agent 团队,包含角色分配、拓扑选择、工具挂载和模型分配
- 三层模型路由:结合 Q-learning 元学习、5 种路由策略和 Bayesian POMDP,在 10 个提供商中动态选择最优模型
- 8 模块质量保障管道:包括共识判断、Goodhart 检测、漂移监控、三难困境逃生舱和行为契约
- 四层内容归属系统:可见署名、HMAC 签名、隐写水印和区块链时间戳
- 通用兼容性:Claw Bridge 支持导入 OpenClaw、NemoClaw、DeerFlow、GitAgent 四种格式,原生支持 MCP 和 A2A 协议
方法论详解
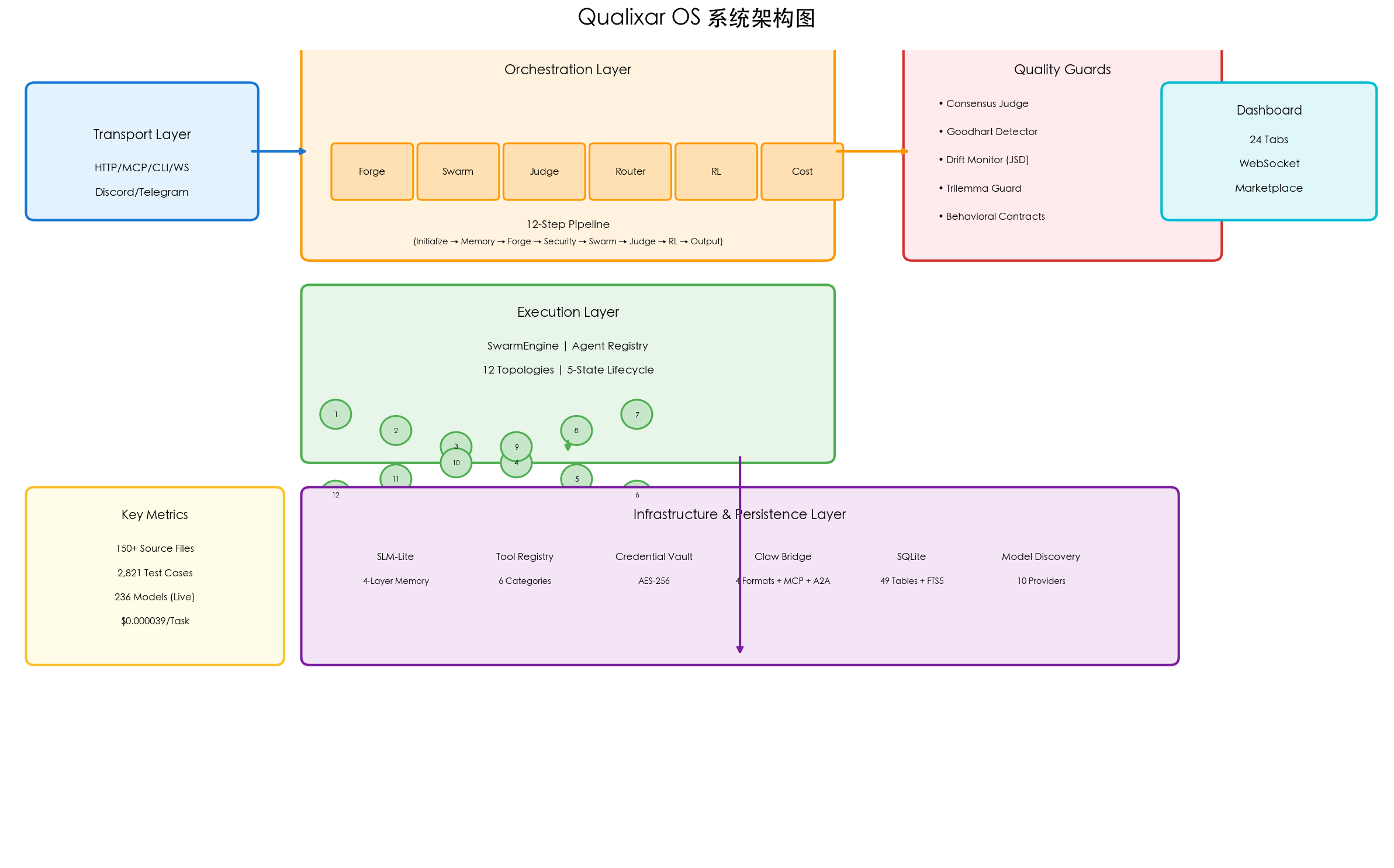
系统架构:六层结构
Qualixar OS 采用六层架构设计:
┌─────────────────────────────────────────────────────────┐
│ Presentation Layer: 24-Tab React Dashboard │
├─────────────────────────────────────────────────────────┤
│ Transport Layer: HTTP/MCP/CLI/WebSocket/Discord... │
├─────────────────────────────────────────────────────────┤
│ Orchestration Layer: 12-Step Pipeline │
│ (Forge → Swarm → Judge → Router → RL → Cost) │
├─────────────────────────────────────────────────────────┤
│ Execution Layer: SwarmEngine + Agent Registry │
│ (12 Topologies, 5-State Lifecycle) │
├─────────────────────────────────────────────────────────┤
│ Infrastructure: SLM-Lite | Tool Registry | Claw Bridge │
├─────────────────────────────────────────────────────────┤
│ Persistence: SQLite (49 tables, FTS5, Event Sourcing) │
└─────────────────────────────────────────────────────────┘12 步编排管道
每个任务都经过 12 步管道处理:
- Initialize:预算检查、任务注册、转向设置
- Memory Injection:通过
autoInvoke()注入 SLM-Lite 上下文 - Forge Design:自动团队组合
- Simulation:可选的预执行模拟(仅 Power 模式)
- Security Validation:策略评估
- Swarm Execution:按拓扑分发 agent
- Judge Assessment:多标准质量评估
- Redesign Loop:拒绝时返回步骤 3(最多 5 次迭代)
- RL Learning:记录复合奖励信号
- Behavior Capture:存储 per-agent 行为模式
- Output Formatting:结果组装和持久化
- Finalize:数据库更新、事件发送、检查点清理
三层模型路由
三层路由架构实现了智能模型选择:
Meta-Layer:ε-贪心上下文 bandit,选择最优路由策略
- 状态编码:
taskTypeHash_modelCountBucket_budgetClass - Q 表持久化到 SQLite
Strategy Layer:5 种路由策略
- Cascade:按质量降序尝试模型
- Cheapest:选择满足质量阈值的最低成本模型
- Quality:选择最高质量分数
- Balanced:质量和成本加权组合
- POMDP:贝叶斯信念状态模型选择
Belief Layer:POMDP 维护三个隐藏状态的信念分布(低/中/高质量上下文)
12 种拓扑详解
| # | 拓扑 | 执行语义 | 终止条件 |
|---|---|---|---|
| 1 | Sequential | 链式 A→B→C | 最后一个 agent 完成 |
| 2 | Parallel | Promise.allSettled | 全部完成 |
| 3 | Hierarchical | 经理分解→工人→合并 | 经理批准 |
| 4 | DAG | 拓扑排序、层级并行 | 所有叶子节点完成 |
| 5 | Mixture | N-1 生成器→1 聚合器 | 聚合器完成 |
| 6 | Debate | 提议者-批评者轮次 | 共识或最大轮次 |
| 7 | Mesh | 全对全广播 | 无新消息或最大轮次 |
| 8 | Star | Hub→Spokes→Hub | Hub 声明完成 |
| 9 | Circular | 环状传递 | 稳定输出或最大轮次 |
| 10 | Grid | 2D 矩阵,4 邻域迭代 | 所有格子稳定或最大轮次 |
| 11 | Forest | 多树递归子→父合成 | 所有根完成 |
| 12 | Maker | 提议→投票(≥66% 通过) | 投票通过或最大轮次 |
创新拓扑
Grid(网格)拓扑:Agent 排列成 2D 矩阵,根据 4 邻域上下文迭代精炼输出——类似细胞自动机动态应用于 LLM 推理。
Maker(创客)拓扑:灵感来自民主决策,提议 agent 生成方案,投票 agent 用结构化 JSON 反馈评估(approved/rejected + 反馈文本),直到达到可配置多数阈值(默认 66%)。
质量保障管道
8 模块评估栈是 Qualixar OS 的核心技术亮点之一:
共识判断管道
4 种内置评估配置:Default、Code、Research、Creative,每种有不同权重。
3 种共识算法:
- 加权多数:按模型能力层级加权
- BFT 风格:要求 ⌊2n/3⌋+1 同意
- Raft 风格:首个判断者作为 leader
Goodhart 检测
Goodhart 定律——「当一个指标变成目标,它就不再是好指标」——对 LLM-as-Judge 系统构成直接威胁。Qualixar OS 监控 4 个信号:
- 跨模型熵:相同输出在不同判断模型上得分高度分歧时触发
- 校准增量:自报置信度和观察准确度之间的差距
- 分数通胀:判断分数超过 RL 奖励模型预测的改进率
- 多样性崩溃:检测重设计团队是否收敛到狭窄的「讨好判断者」配置
漂移监控
使用 Jensen-Shannon 散度追踪判断可靠性:
阈值 ,超过此值时触发干预。
自进化三难困境
Chen et al. 证明:没有对齐方法能同时实现强优化、完美价值捕获和鲁棒泛化。Qualixar OS 实现了 4 个逃生舱:
- 有界改进:RL 奖励信号有上限(∆Q ≤ 0.15/次迭代)
- 安全防火墙:安全策略评估在自改进循环外部
- 对齐锚定:判断配置冻结在显式人工批准之间
- 人工升级:5 次迭代或 3× 预算后升级人工审查
实验与结果
系统规模
| 指标 | 值 |
|---|---|
| 源文件 (.ts + .tsx) | 150+ |
| 测试用例 | 2,821 |
| 数据库表 | 49 (+1 FTS5) |
| API 端点 | 60+ |
| 仪表板标签页 | 24 |
| 事件类型 | 217 |
| 支持拓扑 | 12 |
| 支持提供商 | 10 |
| 实时发现模型 | 236 (Azure AI Foundry) |
| 通信通道 | 7 |
| Marketplace 条目 | 25 |
评估结果
在自定义 20 任务评估套件上,使用 GPT-5.4-mini 达到 100% 准确率,每任务平均成本仅 $0.000039。
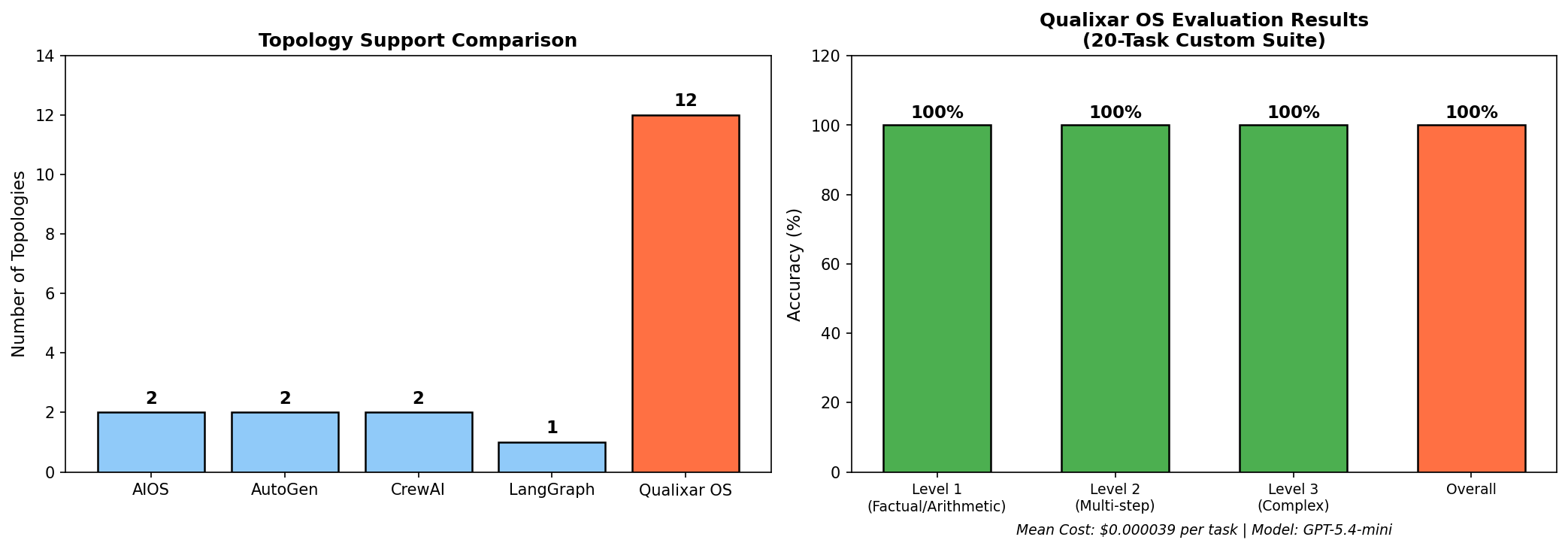
与现有系统对比
| 特性 | AIOS | AutoGen | CrewAI | LangGraph | Qualixar OS |
|---|---|---|---|---|---|
| 拓扑数量 | N/A | 2 | 2 | 1 | 12 |
| 自动团队设计 | ✗ | ✗ | ✗ | ✗ | ✓ |
| 成本路由 | ✗ | ✗ | ✗ | ✗ | ✓ |
| 模型发现 | ✗ | ✗ | ✗ | ✗ | 10 提供商 |
| 质量判断 | ✗ | ✗ | ✗ | ✗ | ✓ |
| Goodhart 检测 | ✗ | ✗ | ✗ | ✗ | ✓ |
| 漂移监控 | ✗ | ✗ | ✗ | ✗ | ✓ |
| 行为契约 | ✗ | ✗ | ✗ | ✗ | ✓ |
| 仪表板 | ✗ | ✗ | ✗ | ✗ | 24 标签页 |
| Marketplace | ✗ | ✗ | ✗ | ✗ | 25 条目 |
启示与思考
我觉得这 paper 最有意思的地方在于它提出的「通用 Type-C 原则」——就像 USB Type-C 统一了充电、数据和视频,一个 agent OS 也应该用单一命令协议统一 CLI、MCP、HTTP、WebSocket 和 Docker 的交互方式。这听起来像是一个工程上的常识,但把它形式化成一个设计原则还是很有启发性的。
不过我也有些保留意见。首先,论文承认自改进循环的基准测试没有显示统计显著收敛(p = 0.578),这是一个诚实但令人失望的结果。其次,100% 的评估准确率来自一个精心策划的 20 任务套件,并不包括网页浏览、文件操作或多工具编排——这意味着在实际复杂场景中的表现还有待验证。
最后,论文作者其实是同一个人写了 AgentAssert、AgentAssay、SkillFortify、SuperLocalMemory v2/v3 和 Qualixar OS 六篇论文——这是一个相当有个人风格的研究项目,贡献了非常完整的技术栈,但也让人好奇这些工作之间的独立验证情况。
无论如何,Qualixar OS 在多框架兼容性和生产就绪度上的努力值得肯定。如果你想在一个统一的系统里同时跑 AutoGen、CrewAI 和 LangGraph 的 agent,它可能是目前最好的选择。