Lean-SMT:给 Lean 接上一台会出证明的 SMT 引擎
Lean-SMT: An SMT tactic for discharging proof goals in Lean
这篇来自 Stanford、Iowa 与 UFMG 等机构的工作,试图把 Lean 中长期缺位的一类自动化补上:把一部分证明目标翻译成 SMT-LIB,交给 cvc5 生成 CPC 证明,再把证明逐步回放成原生 Lean 证明。它的价值不只在于自动化提速,更在于用较小可信基验证外部求解器的证明产物。
论文概览
原文链接: arXiv 2505.15796
作者机构: Stanford University、The University of Iowa、Universidade Federal de Minas Gerais、AWS
主题: Lean 自动化、SMT 证明重建、形式化验证
这篇论文讨论的是一个很朴素、但在证明助手里始终很贵的问题:如何把用户在 Lean 中写下的目标,安全地外包给 SMT 求解器,又把得到的结果重新带回 Lean 内核检查。 Isabelle/HOL 很早就有 Sledgehammer 与 SMT 的集成,而 Lean 虽然生态增长很快,却还缺少同等层级的“一键自动化”能力。Lean-SMT 想补上的,正是这一块基础设施。
论文的核心路线可以写成:
其中, 在 SMT 求解器中被证明为不可满足(unsat),这对应于 的有效性;而最后得到的 Lean 证明仍然要交由 Lean kernel 逐步检查。换句话说,Lean-SMT 并不是“相信 cvc5 说自己是对的”,而是把 cvc5 的证明翻译成 Lean 自己能验的证明对象。
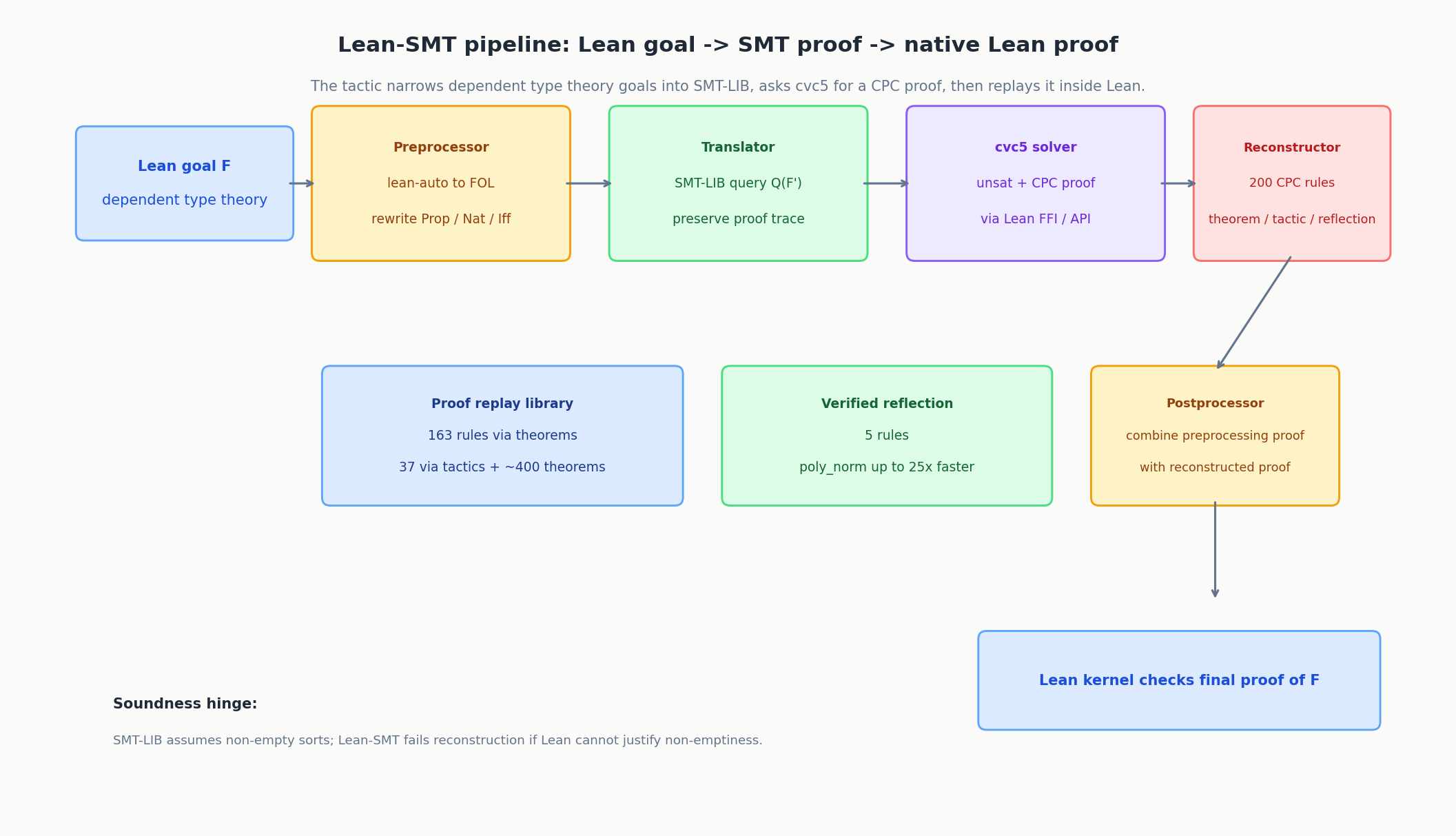
核心创新
1. 把 Lean 的一部分目标压缩进 SMT 可处理片段
Lean 基于依赖类型理论,表达力远强于许多排序一阶逻辑;SMT 求解器则依赖更规则的 SMT-LIB 逻辑。两者之间最大的困难不是“能不能调用求解器”,而是中间的语义缝隙如何补上。论文采用两级预处理:
- 先借助
lean-auto做一阶化(FOL reduction) - 再把
Prop、Nat、Rat、Iff等 Lean 构造改写为更接近 SMT-LIB 的表示
例如,一个带 Group 类型类约束和双向蕴含 ↔ 的 Lean 目标,会被改写成显式群公理 + 等式判断,从而获得可翻译性。这一步不是简单语法糖处理,而是 Lean-SMT 能否工作的入口条件。
2. 不是只收一个 SAT 结果,而是重建一条 Lean 内可验证的证明链
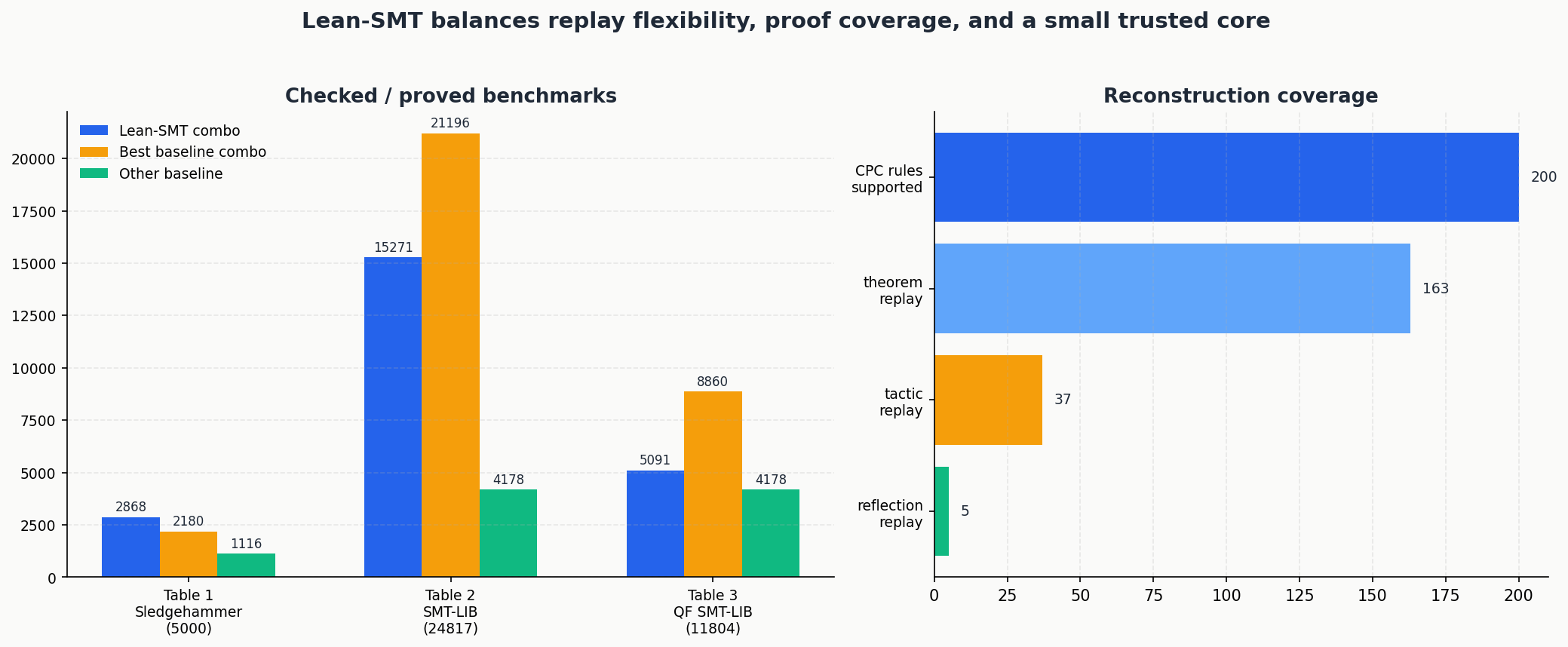
论文真正有分量的部分,在于证明重建(proof reconstruction)。cvc5 输出的是 CPC(Cooperating Proof Calculus)格式证明,Lean-SMT 要逐步把它映射回 Lean 证明。CPC 目前包含 662+ 条 proof rules,而 Lean-SMT 首版支持约 200 条,覆盖比例约 30%。作者没有试图一次吃下全部规则,而是把重建策略拆成三类:
- 定理回放:163 条规则可直接对应为 Lean 定理
- 战术回放:37 条规则需要专门 tactic,背后额外实现了约 400 条辅助定理
- 反射式检查:5 条复杂规则交给经过 Lean 验证的反射程序处理
这种分层很关键。因为它说明 Lean-SMT 并不依赖一个巨大、僵硬的验证器,而是把“可直接重放”“需要策略化重放”“适合反射计算”的三类证明步骤分开治理。
3. 用较小可信基换取比完全外部检查器更强的内聚性
论文反复强调 trusted core。SMTCoq 这类系统也很可信,但其路径更接近“在证明助手内部运行一个经过验证的检查器”;Lean-SMT 则更偏向 proof replay:把外部求解器的每一步证明动作重放为 Lean 自己的证明步骤。
这条路线的优点有两个:
- 当 cvc5 的 proof calculus 继续演化时,只需要增量修改重建逻辑,而不必重做整套检查器正确性证明。
- 最终的正确性仍然落回 Lean kernel,而不是落在某个额外的大型运行时上。
这正是论文所说的“小可信基”:Lean-SMT 追求的不是绝对最快,而是在自动化、灵活性和可信度之间寻找工程上更均衡的支点。
方法论详解
系统流水线
Lean-SMT 的架构可以概括成四段:
- Preprocessor:把原始 Lean 目标 化简为更适合翻译的
- Translator:把 变成 SMT-LIB 查询
- Solver:调用 cvc5,获取 unsat 结论与 CPC 证明
- Reconstructor + Postprocessor:把 CPC 证明回放成 Lean 证明,并与预处理证明拼接,得到原始目标的最终证明
对应的伪代码大致如下:
input_goal = F
reduced_goal, pf_pre = preprocess(F)
smt_query = translate_to_smtlib(reduced_goal)
cpc_proof = cvc5_prove_unsat(smt_query)
pf_replay = reconstruct_in_lean(cpc_proof)
final_proof = compose(pf_pre, pf_replay)
lean_kernel.check(final_proof)关键难点一:Lean 与 SMT-LIB 的逻辑假设不同
一个非常重要、也很容易被忽略的细节是:SMT-LIB 默认所有 sort 非空,而 Lean 允许类型为空。 这意味着翻译如果处理得粗糙,可能会产生“SMT 里可证,Lean 里并不成立”的假阳性。
论文的解决思路不是在翻译阶段武断补假设,而是在重建阶段检查非空性依赖。若某个证明步骤依赖某个类型非空,而 Lean 无法证明这一点,重建就失败。这种设计把风险从“静默不 sound”改成“明确无法回放”,是相当稳妥的选择。
关键难点二:复杂规则不能只靠枚举定理
并非所有 CPC 规则都适合直接写成定理。以 ARITH_SUM_UB 为例,它允许混合 <、≤、=,并同时处理 Int 与 Real。如果把所有组合都显式编码,会迅速爆炸。作者于是引入 tactic 组合与多态定理,把这些组合压缩进一组参数化结构中。
另一个亮点是 poly_norm。这是为算术规范化写的反射式程序,论文报告其在大表达式上可比直接依赖 definitional equality 快 25 倍。这说明 Lean-SMT 并不只是做“翻译胶水”,而是在证明回放层认真处理性能热点。
实验与结果
论文用两类基准评估 Lean-SMT:
- 5000 个来自 Isabelle Sledgehammer 的 SMT 基准
- 24817 个 SMT-COMP 2024 中属于支持片段的无满足性基准
基准一:对齐 Sledgehammer 的问题集
在 5000 个 Seventeen Provers benchmarks 上:
| Solver + Checker | Solved & Proved | Checked | Checked (no holes) |
|---|---|---|---|
| cvc5 + Lean-SMT | 2868 | 2866 | 2847 |
| veriT + Sledgehammer | 2211 | 2180 | 2180 |
| Duper | 1116 | 1116 | 1116 |
论文指出,Lean-SMT 在这组数据上优于 veriT + Sledgehammer,主要原因不是回放器“更神”,而是 cvc5 在这类基准上本身比 veriT 更强。另外,Lean-SMT 对 98% 的基准都能在 1 秒内 完成 proof replay,剩余 2% 也都在 5 秒内。
基准二:SMT-LIB 证明检查
在 SMT-LIB 支持片段上,结果更能体现它作为 proof checker 的位置:
| Solver + Checker | Solved & Proved | Checked | Checked (no holes) |
|---|---|---|---|
| cvc5 + Lean-SMT | 21595 | 15271 | 14099 |
| cvc5 + Ethos | 21541 | 21196 | 18018 |
| veriT + SMTCoq | 4178 | 4178 | 4178 |
如果只看量级,Lean-SMT 仍落后于 Ethos:作者给出的数字是 71% 对 98%。但论文的重点不是宣称“已经全面超越现有检查器”,而是说明:在坚持 Lean kernel 作为最终裁判的前提下,它已经能覆盖足够广的片段,并把性能控制在同一数量级。
对量化自由(quantifier-free)子集,Lean-SMT 也给出了单独结果:在 11804 个基准中,cvc5 + Lean-SMT 检查了 5091 个证明,而 cvc5 + Ethos 为 8860,veriT + SMTCoq 为 4178。这再次说明 Lean-SMT 的优势不在极致速度,而在更灵活的规则适配能力与更统一的 Lean 内部集成。
综合判断
Lean-SMT 最重要的贡献,并不是“Lean 终于也能调 SMT 了”这样一句表面上的功能补齐,而是它给出了一种相当务实的工程路径:先限制逻辑片段,再把外部求解器的证明逐步转写成内部证明对象,让自动化提升与可信验证同时成立。
这类系统的价值,往往出现在两个地方。
第一,它降低了形式化验证的交互成本。很多证明目标并不深奥,只是繁琐;如果能稳定地下沉给 SMT 求解器,再把结果带回 Lean,形式化工作的门槛会明显下降。第二,它给 Lean 生态铺了一条通向“Lean 版 Sledgehammer”的路。论文已经把前半段路线图写清楚:扩展更多 SMT 理论、覆盖更多 proof rules、加强与 lean-auto 的配合,并逐步触达更高阶逻辑与常见 Lean 数据类型。
当然,它的局限也非常清楚:当前只支持约 200 条 CPC 规则;对 bit-vectors、floats、strings 等理论还没有完整支持;而且 lean-auto 与后续预处理之间仍存在片段边界。这意味着 Lean-SMT 现在更像一套有明确方向、性能扎实、可信边界清楚的基础设施原型,还不是一把可以覆盖 Lean 日常证明工作的万能锤子。
但对形式化方法而言,这恰恰是更值得肯定的状态:它没有用夸张的“全自动证明”口号替代细节,而是老老实实把翻译、证明、回放、可信基和实验数据一层一层交代清楚。这样的系统,反而更可能真正长成基础设施。