GEPA:用反思式提示进化超越强化学习
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
GEPA(Genetic-Pareto)是一个提示优化器,通过自然语言反思替代权重空间的强化学习。在六个基准任务上,GEPA 平均超越 GRPO 6%、最高超越 20%,同时仅使用最多 35 倍更少的 rollout;相比最优提示优化器 MIPROv2 也高出 10% 以上。ICLR 2026 Oral。
论文概览
大语言模型(LLM)适配下游任务的主流路径,是通过 GRPO 等强化学习(RL)方法在可验证奖励信号下更新权重。这条路有效,但代价高昂:典型 GRPO 实验动辄消耗数万甚至数十万条 rollout,而当目标模型不可微调、推理预算有限,或工具调用代价高时,权重空间的优化就变成了奢侈品。
来自 UC Berkeley、Stanford、MIT 等机构的研究者在 ICLR 2026 上提出了另一条路:把优化从参数空间迁移到自然语言空间。他们的系统 GEPA(Genetic-Pareto Prompt Optimizer)通过对执行轨迹进行反思,在自然语言层面不断演化 prompt,而非调整模型权重。
核心主张很直接:LLM 的 rollout 本质上就是一段可读文本,里面已经包含了推理链、工具调用、编译器报错等丰富的诊断信息——这些信息远比一个稀疏的标量奖励更有内容。与其把它压缩为策略梯度信号,不如直接让 LLM 读懂它、反思它、修改 prompt。
核心结果(Qwen3 8B):
- 在六个任务上平均超越 GRPO(24,000 rollouts)+6%,最高 +20%
- 所用 rollout 最多减少 35×(平均约 700 条)
- 相比最优提示优化器 MIPROv2,综合提升 +13%(GEPA+Merge)
- 支持闭源模型(GPT-4.1 Mini),prompt 可跨模型迁移
核心创新
创新一:反思式提示变异(Reflective Prompt Mutation)
GEPA 的核心操作单元。给定一个候选 prompt,GEPA 在小批量训练数据上执行系统,收集:
- 执行轨迹:LLM 的推理链、中间输出
- 评估轨迹:编译器错误、失败的 rubric 条目等文本反馈(在标量奖励计算前产生)
然后用一个"反思 LM"接收 (当前 prompt, 轨迹, 分数, 文本反馈),输出一个改进后的新 prompt。如果新 prompt 在小批量上分数提升,才进入候选池参与全量验证。
与 TextGrad、MIPROv2 等方法的关键差异:GEPA 利用评估轨迹(如编译器报错)作为额外诊断信号,而不仅依赖最终标量奖励。
创新二:帕累托前沿候选选择(Pareto-based Candidate Selection)
朴素的贪心策略(每次选最优候选变异)极易陷入局部最优:一旦找到一个好策略,后续 rollout 都在尝试进一步优化它,却难以突破。
GEPA 维护一个帕累托前沿:对每个训练实例,记录所有候选中的最高分;只保留"在至少一个实例上是最优"的候选(非支配集)。从这个剪枝后的集合中按"出现频次"加权随机采样下一个待变异的候选。
这保证了搜索的多样性:不同候选代表不同的"赢法",组合迁移潜力更大。消融实验显示,相比贪心选择(SelectBestCandidate),Pareto 选择聚合提升 +7.33%;相比 BeamSearch(N=4)提升 +6.4%。
创新三:系统感知交叉(System-Aware Merge / GEPA+Merge)
对于含多个 LLM 模块的复合系统,两个候选可能各自学到了互补策略——A 的第一个模块更好,B 的第二个模块更好。GEPA 检测此类情况并执行"系统感知交叉":只合并来自共同祖先、优化了不同子集模块的帕累托最优候选对,避免无效合并。
| 方法 | HotpotQA | IFBench | HoVer | PUPA | AIME | LiveBench | 综合提升 |
|---|---|---|---|---|---|---|---|
| Baseline | 42.33 | 36.90 | 35.33 | 80.82 | 27.33 | 48.70 | — |
| GRPO | 43.33 | 35.88 | 38.67 | 86.66 | 38.00 | 51.26 | +3.68 |
| MIPROv2 | 55.33 | 36.22 | 47.33 | 81.55 | 20.00 | 46.60 | +2.61 |
| GEPA | 62.33 | 38.61 | 52.33 | 91.85 | 32.00 | 51.95 | +9.62 |
| GEPA+Merge | 64.33 | 28.23 | 51.67 | 86.26 | 32.00 | 51.95 | +7.17 |
方法论
形式化定义
GEPA 将复合 AI 系统形式化为 ,其中:
- :语言模块序列
- :控制流逻辑(决定模块调用顺序)
- :全局输入输出模式
每个模块 ,其中 是 prompt, 是权重。
优化目标(在 rollout 预算 约束下):
GEPA 固定权重 ,只优化 prompt 集合 。
核心算法(伪代码)
GEPA(Φ, D_train, μ, μ_f, B):
D_feedback, D_pareto = split(D_train)
P = [Φ] # 候选池(初始只有原始系统)
S_Φ[i] = μ(Φ(x_i), m_i) # 初始验证分数
while budget B not exhausted:
k = SelectCandidate(P, S) # Pareto 候选选择
j = SelectModule(Φ_k) # round-robin 模块选择
M = minibatch from D_feedback
# 收集执行+评估轨迹及文本反馈
feedback, scores, traces = run(Φ_k[j], M, μ_f)
# 反思 LM 生成新 prompt
π_j' = UpdatePrompt(π_j, feedback, traces[j])
Φ' = copy of Φ_k with module j replaced by π_j'
if avg_score(Φ', M) > avg_score(Φ_k, M):
# 小批量验证通过,全量评估后加入候选池
add Φ' to P
S_Φ'[i] = μ(Φ'(x_i), m_i) for each i in D_pareto
return Φ* maximizing avg score on D_pareto反思提示元模板(Meta Prompt)
I provided an assistant with the following instructions to perform a task:
<current instruction>
The following are examples of task inputs + assistant responses + feedback:
<Inputs, Outputs and Feedback for minibatch>
Your task: write a new instruction for the assistant.
Read all responses and feedback. Identify niche/domain-specific factual information.
If the assistant used a generalizable strategy, include it in the instruction.
Provide the new instructions within ``` blocks.实验结果
主要对比(Qwen3 8B)
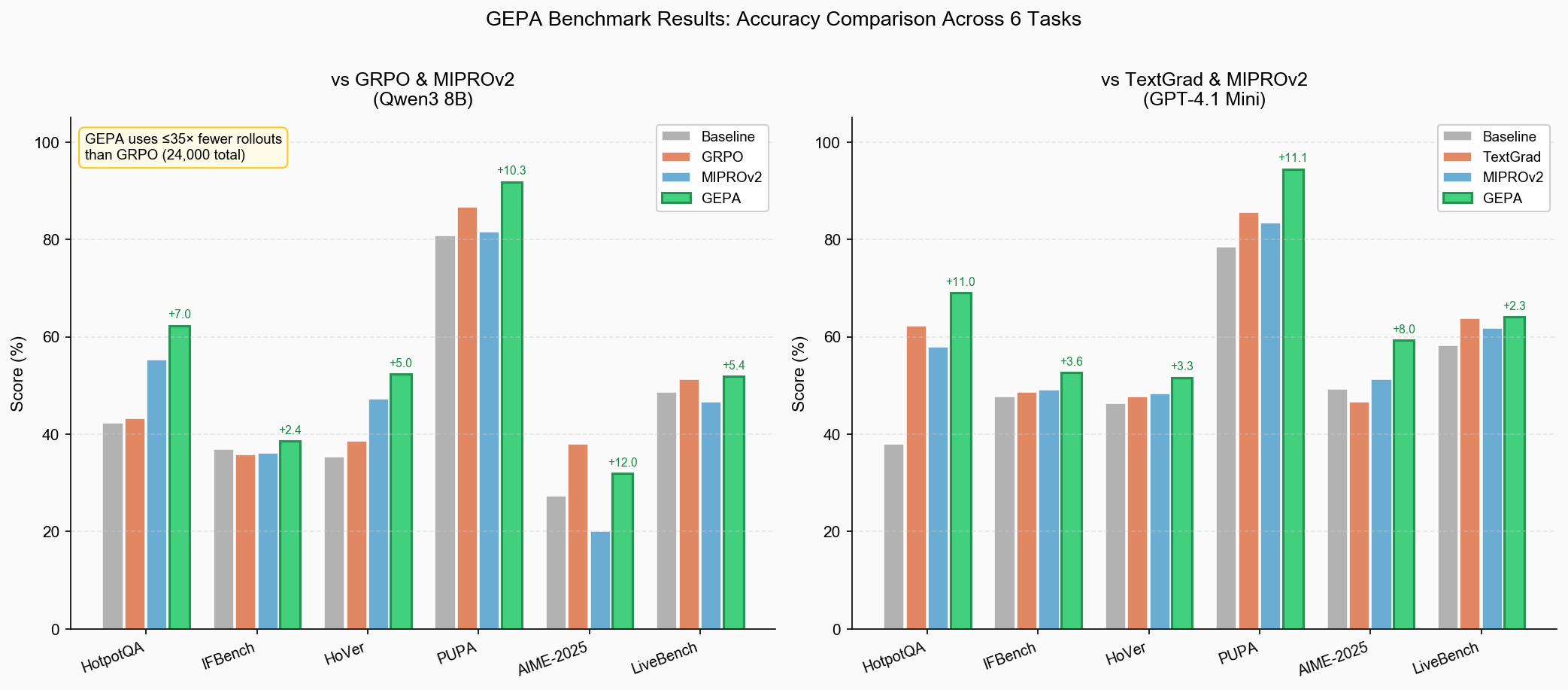
GEPA 在六项任务中的五项(HotpotQA +19%、HoVer +13.66%、PUPA +5.19%、IFBench +2.73%、LiveBench +0.7%)超越 GRPO,仅 AIME 一项落后于 GRPO(32% vs 38%)——而 GEPA 在 AIME 上所用 rollout 仅 1,839 条,GRPO 则用了 24,000 条。
样本效率对比
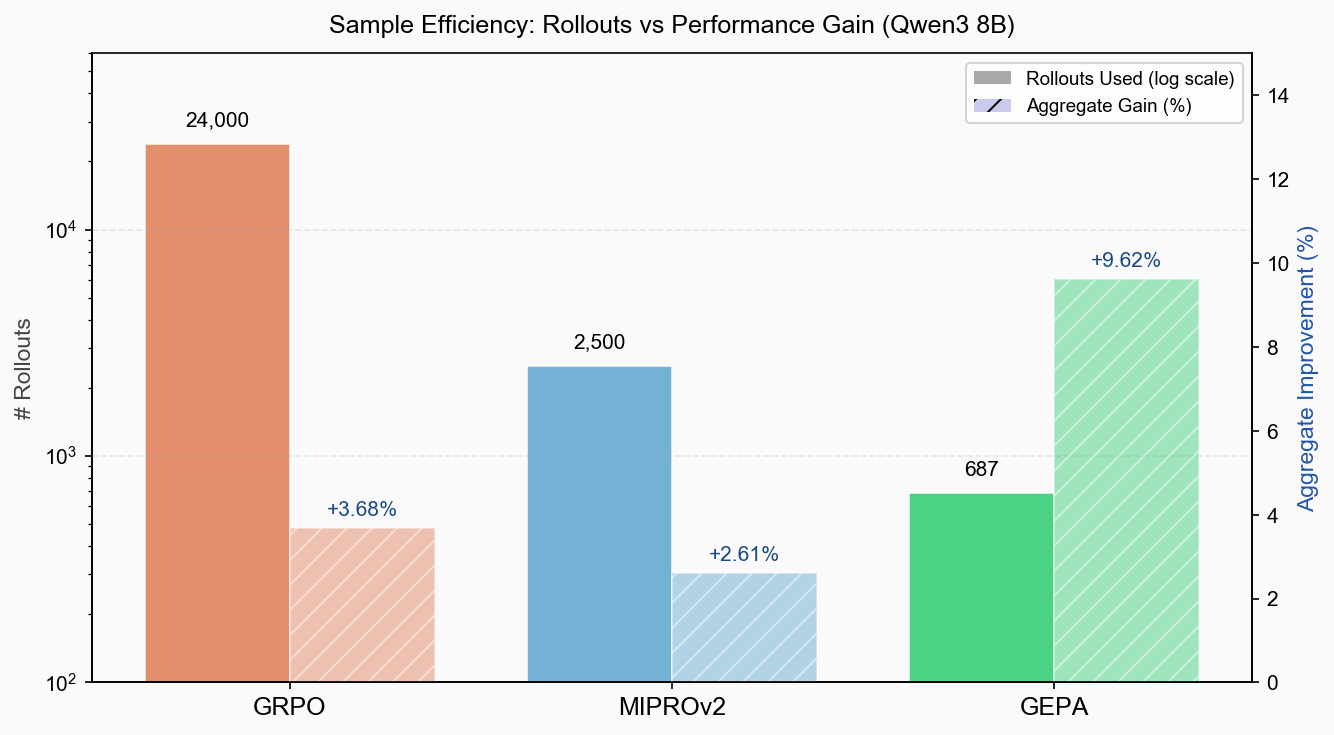
GEPA 平均仅使用约 687 条 rollout(GRPO 为 24,000 条),即实现了更高的综合提升(+9.62% vs +3.68%)。训练集 rollout 更少——在部分任务上只需 6 到 102 条训练样本即可匹敌 GRPO 的最佳验证分数。
跨模型迁移
"GEPA-Qwen-Opt" 是完全基于 Qwen3 8B 优化的 prompt,直接用于 GPT-4.1 Mini 评估(不做任何修改),仍比直接针对 GPT-4.1 Mini 优化的 MIPROv2、TextGrad、Trace 方法更高:综合提升 +9%,超过 TextGrad(+6.11%)和 MIPROv2(+5.64%)。这说明 GEPA 学到的 prompt 不是在拟合特定模型,而是在提炼任务本身的规律。
消融:候选选择策略
| 策略 | HotpotQA | IFBench | HoVer | PUPA | 综合提升 |
|---|---|---|---|---|---|
| Baseline | 42.33 | 36.90 | 35.33 | 80.82 | — |
| SelectBestCandidate | 58.33 | 30.44 | 45.33 | 85.45 | +6.05 |
| BeamSearch (N=4) | 57.33 | 36.39 | 41.00 | 81.08 | +5.11 |
| GEPA (Pareto) | 62.33 | 38.61 | 52.33 | 91.85 | +12.44 |
延伸应用:推理时搜索
GEPA 的进化框架还可用于推理时代码优化(NPUEval、KernelBench),此时每个 candidate 不是 prompt 变体,而是代码变体,fitness 是运行时性能(GFLOPS、内存带宽)。这将 GEPA 从训练时优化器扩展为推理时搜索策略。
启示与思考
语言是更丰富的学习介质
GEPA 的成功在某种程度上是对 RL 范式的一次"降维反问":RL 把 LLM 的丰富输出压缩为一个标量,再用这个标量估计策略梯度;GEPA 则问"为什么要扔掉这些信息?"——用 LLM 自己读懂执行轨迹、理解失败原因,然后直接用自然语言写出更好的指令。
从信息论角度看,这不是奇怪的,这是自然的:当目标空间本身是语言,那么在语言空间中学习应当比在权重空间中学习更直接。GRPO 的权重更新隐含了大量归纳偏置,而 GEPA 的反思提示则可以直接利用任务的领域知识。
提示越短,泛化越好
GEPA 产生的 prompt 长度比 MIPROv2 短 9.2×,但性能更高。这对实际系统有双重价值:推理成本下降(按 token 计费),泛化间隙(validation–test gap)也更小。MIPROv2 的 few-shot 示例相当于在 prompt 里塞入了大量训练数据,而这些数据对模型是否真的必要,值得质疑。
什么时候 GRPO 更有优势?
GEPA 在 AIME 数学推理上不及 GRPO(32% vs 38%)。GRPO 通过权重更新可以修改模型内部的推理链偏好,而 GEPA 只能改 prompt——如果任务要求的是深度内化的推理模式(如数学符号操作),prompt 能传达的信息量有限。这是当前 GEPA 的边界:对于 prompt-expressible 的任务优势显著,对于 weight-only-expressible 的能力则力所不及。
未来方向
论文提出了几个扩展方向值得关注:
- 动态验证集采样:目前大量 rollout 用于全量验证集评估,通过动态子集选择可进一步提升效率
- GEPA + GRPO 联合优化:提示优化与权重优化并非互斥,两者结合(Multi-Module GRPO,见附录引用的并行工作)可能取长补短
- 推理时搜索泛化:GEPA 作为推理时代码优化器已展示潜力,向更广泛的推理时搜索扩展是自然延伸