形式化智能体AI系统的安全性与功能性属性
Formalizing the Safety, Security, and Functional Properties of Agentic AI Systems
本文针对当前 AI 智能体协议碎片化问题,提出宿主智能体模型与任务生命周期模型,为多 AI 智能体系统提供统一的语义框架,并形式化定义了 30 个关键属性(16 个宿主智能体属性 + 14 个任务生命周期属性),涵盖活性、安全性、完整性与公平性四大类别。
论文概览
本文要回答一个我思考已久的问题:当多个 AI 智能体通过网络协议协同工作时,我们如何能够确保整个系统的行为是可预测的、安全的、可靠的?
作者来自罗马大学(Sapienza)和普渡大学,指出当前智能体间通信生态的一个根本性缺陷——碎片化。MCP(Model Context Protocol)和 A2A(Agent-to-Agent)协议被孤立分析,缺乏统一的语义层,导致架构错位、可利用的协调漏洞等风险长期存在。
本文的核心贡献是提出一个由两个形式化模型组成的建模框架:
- 宿主智能体模型(Host Agent Model):形式化与用户交互的顶级实体,该实体分解任务并通过外部智能体和工具编排执行
- 任务生命周期模型(Task Lifecycle Model):详细描述子任务从创建到完成的状态与转换,提供细粒度的任务管理和错误处理视图
原文链接:arXiv 2510.14133
核心创新
创新点 1:首次为多智能体 AI 系统建立统一的语义框架
过去的研究要么聚焦于 MCP(工具调用),要么聚焦于 A2A(智能体间通信),但没有人在协议无关的层面上形式化整个系统的行为模型。本文首次将两个协议纳入同一个语义框架中分析,指出它们之间存在的语义鸿沟:
- 任务交接失败:从 A2A 委托智能体到 MCP 调用智能体的任务转移容易失败(例如参数格式不兼容)
- 不一致的状态管理:没有统一视图,追踪多协议任务的状态变得不可靠
创新点 2:30 个形式化属性的系统化定义
在两个模型的基础上,论文定义了16 个宿主智能体属性和14 个任务生命周期属性,分为四类:
- 活性(Liveness):确保系统最终取得进展
- 安全性(Safety):确保智能体永远不会进入全局无效或有害状态
- 完整性(Completeness):保证系统能找到有效的解决方案
- 公平性(Fairness):确保所有外部操作最终终止
所有属性均用时序逻辑(CTL/LTL)表达,使得形式化验证成为可能。
创新点 3:案例研究验证对抗性攻击的防御点
论文通过一个自动化金融规划器场景,展示了 4 个控制点如何协同防御:
- 宿主智能体核心(HAC):意图澄清阶段作为提示注入攻击的守卫
- 注册表(Registry):作为信任锚,缓解供应链风险
- 编排器(Orchestrator):运行时监控委托依赖 DAG
- 通信层(CL):零信任架构,每条调用需要可验证身份
方法论详解
宿主智能体模型
宿主智能体模型 是一个七元组:
其中每个组件都有明确的语义:
| 组件 | 定义 | 作用 |
|---|---|---|
| 自主智能体集合 | A2A 协议中的服务器节点 | |
| 外部实体集合 | 包括功能工具(MCP)和 | |
| 注册表 | 维护外部实体到能力配置文件的映射 | |
| 宿主智能体核心(HAC) | 负责意图解析: | |
| 编排器 | 任务分解与聚合: | |
| 通信层 | 协议无关的安全交互: |
核心执行流程:
# 宿主智能体执行序列
def execute(user_request: Req_U):
# 1. 意图解析
intent = hac.interpret(user_request)
# 2. 任务分解:LLM 构建 DAG
dag = orchestrator.build_task_dag(intent, registry.discover())
# 3. 分布式执行
for sub_task in dag.topological_order():
if sub_task.protocol == "A2A":
result = cl.invoke_a2a(sub_task.agent, sub_task.payload)
else: "# MCP"
result = cl.invoke_mcp(sub_task.tool, sub_task.payload)
# 4. 结果聚合
return orchestrator.aggregate(results)任务生命周期模型
任务生命周期模型 是一个有限状态机,定义了子任务从创建到终止的完整轨迹:
状态空间 包含 11 种状态:
CREATED → AWAITING_DEPENDENCY → READY → DISPATCHING → IN_PROGRESS
↓
COMPLETED / FAILED
↓
RETRY_SCHEDULED / FALLBACK_SELECTED
↓
ERROR / CANCELED (terminal)关键状态约束(以 CTL 公式表达):
-
TL₇(进入 DISPATCHING 的合法性):
-
TL₉(ERROR 状态不可逆):
-
TL₁₂(无回退的 FAILED 转换路径):
这些约束共同确保了任务在任意状态下的转换都是合法且可追踪的。
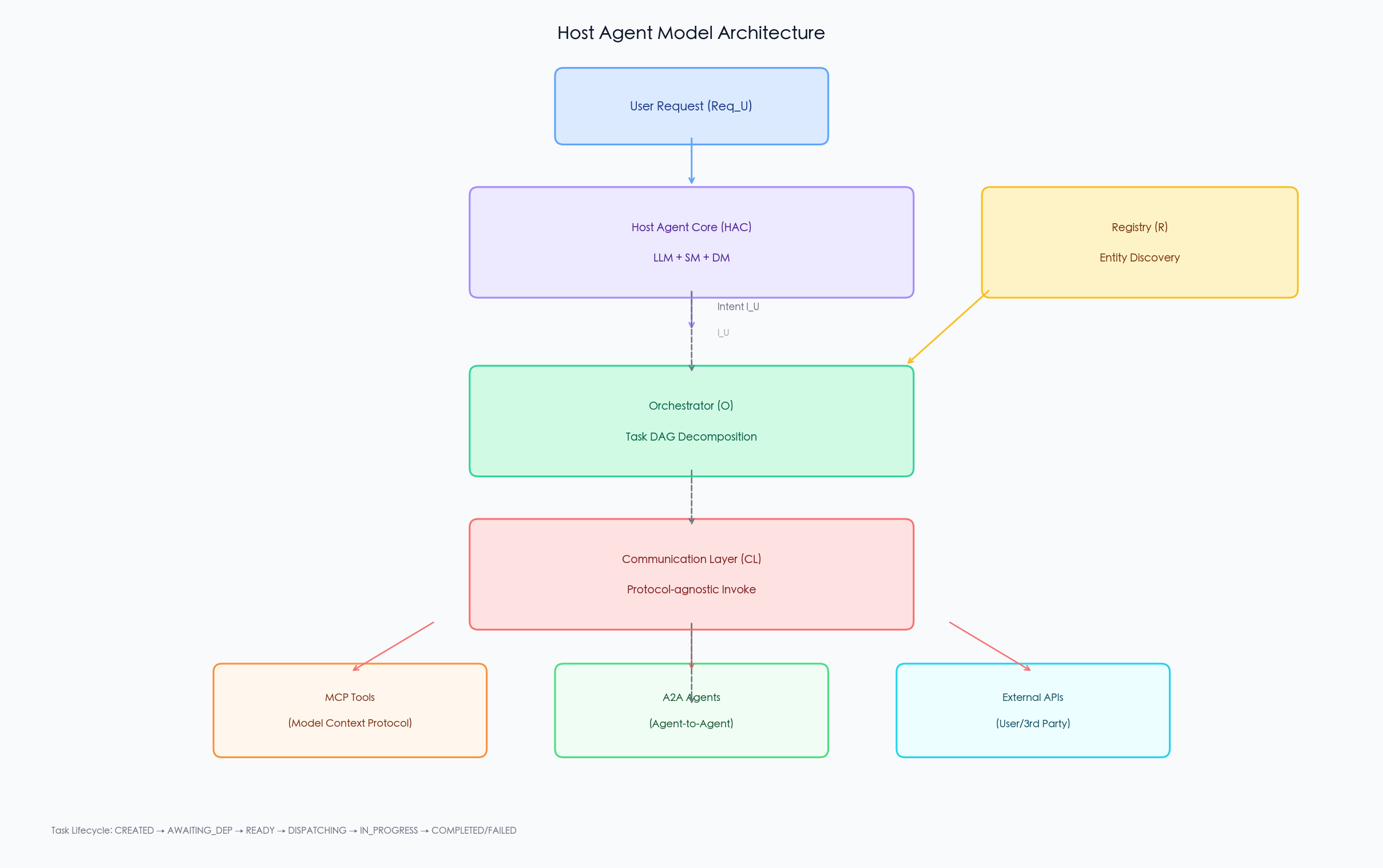
图 1:宿主智能体模型的核心组件与数据流向
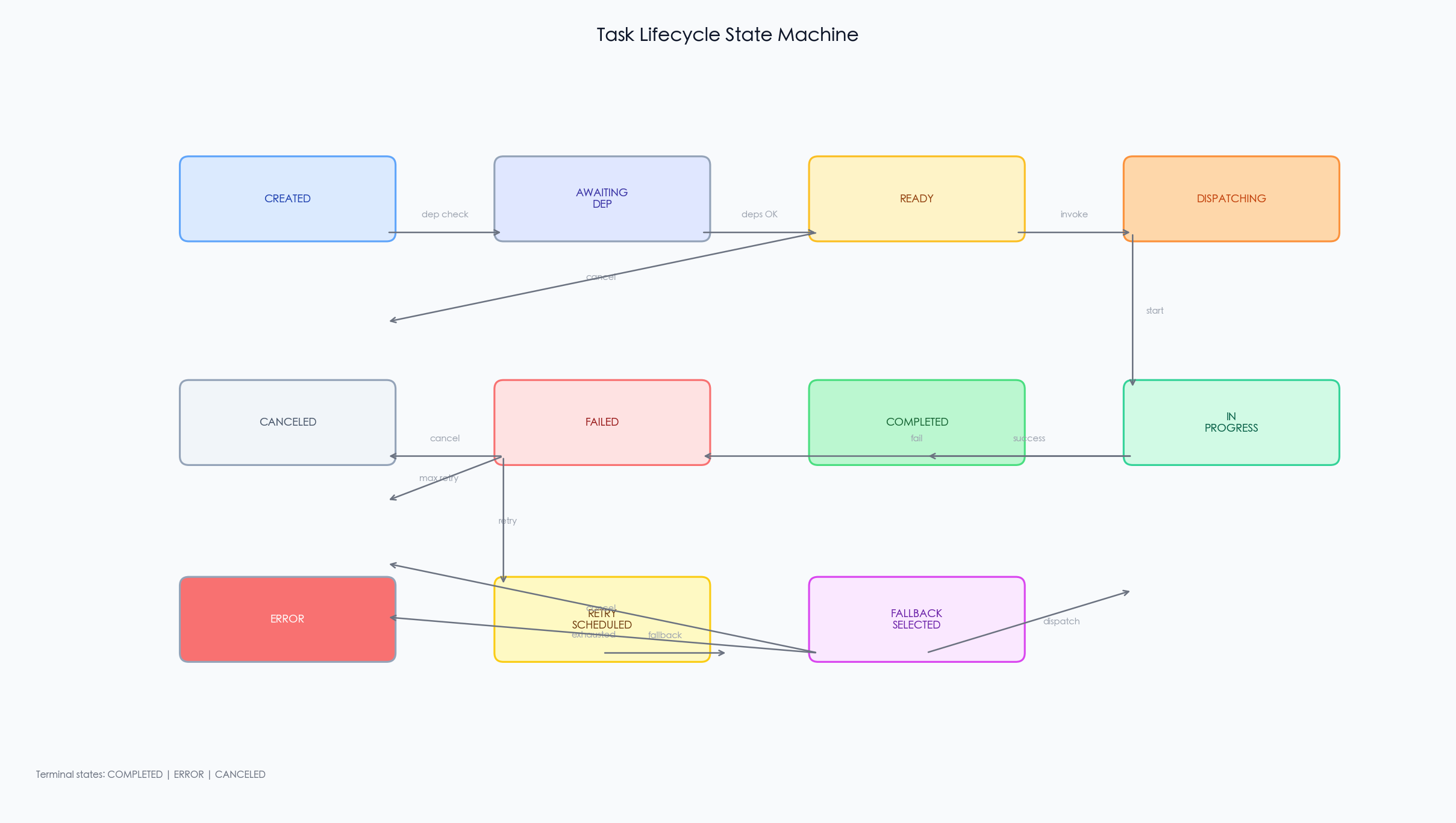
图 2:任务生命周期模型的 11 种状态及转换关系
关键属性分类
宿主智能体属性(16 个)
**活性属性(HP₁–HP₆)**确保系统最终完成工作:
- HP₁:每个用户提示最终收到宿主智能体的响应
- HP₂:HAC 最终澄清每个用户提示的意图
- HP₃:意图澄清后,LLM 最终构建任务 DAG
- HP₄:任务 DAG 中所有子任务最终被调用
- HP₅:每个被调用的子任务最终产生结果
- HP₆:所有子任务结果最终被编排器聚合
**安全性属性(HP₇–HP₁₁)**防止非法行为:
- HP₇:任务 DAG 仅在实体被注册表发现后才构建
- HP₈:子任务仅在 DAG 明确包含时才被调用
- HP₉:任务调用以 EE 完成系统预定义验证为条件
- HP₁₀:子任务仅在无未完成依赖时才被调用
- HP₁₁:宿主智能体响应仅在所有子任务调用后才返回
任务生命周期属性(14 个)
**活性属性(TL₁–TL₆)**确保任务推进:
- TL₁:每个 CREATED 子任务最终终止于 COMPLETED/ERROR/CANCELED
- TL₅:子任务不能无限期停留在 AWAITING DEPENDENCY
- TL₆:依赖满足的 AWAITING DEPENDENCY 最终转换到 READY
**安全性属性(TL₇–TL₁₁)**确保状态转换合法:
- TL₈:子任务仅在先前状态为 IN PROGRESS 时才能进入 COMPLETED
- TL₁₀:子任务仅在其先前状态为 FAILED 时才能进入 RETRY SCHEDULED
启示与思考
读完这篇论文,我有几个感受。
第一,这项工作填补了一个我之前没有清晰意识到的空白。我一直在关注单个智能体的安全问题(提示注入、越狱),但忽略了多智能体协作层面的系统性风险。当一个智能体可以委托另一个智能体,而后者又调用外部工具时,攻击面是指数级增长的。这篇论文让我意识到,协议碎片化本身就是一种安全风险——不是某个协议有漏洞,而是协议之间缺乏统一的语义层。
第二,我对作者选择的时序逻辑框架感到信服。CTL/LTL 是成熟的模型检测工具(如 NuSMV、UPPAAL)所支持的语言,这意味着论文中定义的 30 个属性可以直接被形式化验证工具检查。这不是一篇纯理论论文——它为工程实践铺设了坚实的桥梁。
第三,论文的局限性也值得注意。目前的属性是规范层面的(描述"应该"怎样),而不是实现层面的(检查"实际"系统是否满足)。作者在结论中提到未来将从代码自动导出形式化模型,这是一个更有挑战性的方向——静态分析 LLM 生成的任务 DAG 可不比模型检测简单。
最后,我想说,这篇论文的工作量是惊人的——系统性地定义了 30 个属性,覆盖两个协议、两个模型、四类属性维度。这不是一个简单的工作,而是一个真正为领域奠定基础的框架性研究。对于任何正在构建多智能体系统的人来说,这是一篇必读论文。
参考资源
- 原文:arXiv 2510.14133v2
- MCP 协议:Model Context Protocol (Anthropic)
- A2A 协议:Agent-to-Agent Protocol (Google Cloud)
- OWASP AgentAI 安全风险 Top 10:链接
标签:#AI解读 #Agent架构设计 #形式化验证 #多智能体系统 #AI安全