FM-Agent:用 LLM 把形式化验证 Scale 到大厂级别代码库
FM-Agent: Scaling Formal Methods to Large Systems via LLM-Based Hoare-Style Reasoning
上海交大提出 FM-Agent,首个利用 LLM 实现大规模系统自动化组合式验证的框架。在 143k LoC 规模系统中发现 522 个新 bug。
原始标题:FM-Agent: Scaling Formal Methods to Large Systems via LLM-Based Hoare-Style Reasoning 作者:Haoran Ding, Zhaoguo Wang, Haibo Chen(上海交通大学并行与分布式系统研究所) 发表:arXiv 2604.11556,2026 原文:PDF 链接
论文概览
LLM 生成代码的能力越来越强——已经能写出十万行级别的大型系统,比如一个完整的编译器 CCC。但这里有个根本矛盾:LLM 会产生幻觉,而形式化验证(formal methods)恰恰是用来证明代码「没有这类错误」的最严格手段,可它从来就不是为大规模系统设计的。
传统形式化验证依赖 Hoare 逻辑——思路是把大系统拆成小模块,分别验证。问题在于:Hoare 逻辑要求为每个函数写出精确的形式化规格,这件事本身就对人类构成巨大负担。当代码是 LLM 生成的时候,情况更糟——开发者自己都不清楚每个函数「应该做什么」,规格写得不对,验证就毫无意义。
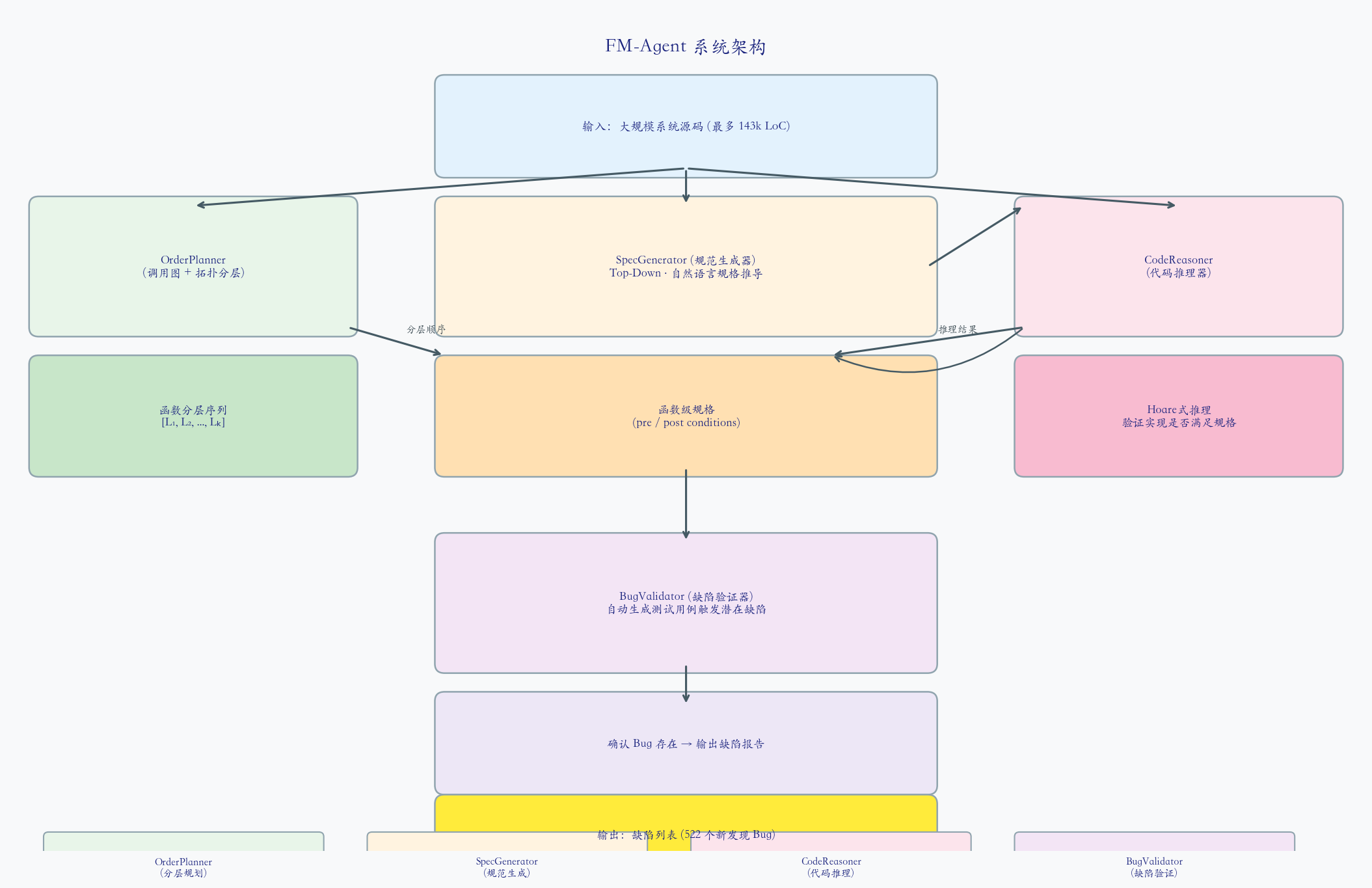
FM-Agent 想解决的就是这件事:让 LLM 自己学会写规格、自己做 Hoare 推理、自己发现 bug。
核心创新
- 自顶向下(Top-Down)规格推导:不是让 LLM 孤立地「读代码写规格」,而是从调用者的期望出发,反推被调函数的规格。这样即使实现有 bug,规格依然能反映开发者的真实意图。
- 自然语言规格的 Hoare 式推理:将 Hoare 推理泛化到自然语言规格上,让 LLM 能在「规格说了什么」和「代码做了什么」之间做严格对应。
- 自动缺陷验证:推理发现了潜在问题?自动生成能触发该问题的测试用例,确认 bug 真实存在,并给出触发路径。
- 分层并行规格生成:通过调用图拓扑分层,让没有依赖关系的函数可以并行处理规格生成。
方法论详解
OrderPlanner:分层规划
规格生成不是「把所有函数一起丢给 LLM」——存在调用依赖关系。FM-Agent 第一步构建调用图,做拓扑分层:
def OrderPlanner(F):
⟨V, E⟩ = ConstructCallGraph(F)
SCCs = FindSCCs(⟨V, E⟩)
⟨V', E'⟩ = CondenseGraph(SCCs)
indeg = getIndegree(⟨V', E'⟩)
Q = {v | indeg(v) = 0}
layers = []
while Q ≠ ∅:
layers.append(Q)
Q = getNextLayer(Q, indeg)
return layers分层保证了:当你生成某函数的规格时,所有调用它的函数规格已经就绪——这正是自顶向下的核心。
SpecGenerator:规格生成器
传统方法让 LLM 读函数实现然后「猜测」规格;FM-Agent 让 LLM 从调用者的视角反推。对于函数 ,LLM 综合调用点上下文、文档注释、类型签名来生成前置/后置条件对。
CodeReasoner:代码推理器
传统 Hoare 逻辑将程序执行拆解成一步步的逻辑推演——给定前置条件 、程序 、后置条件 ,通过执行和条件验证来证明正确性。FM-Agent 将这个过程交给 LLM,但要求 LLM 像做 Hoare 推理那样为每一步提供理由,而不只是说「这段代码看起来对」。
BugValidator:缺陷验证器
推理发现了「代码可能不满足规格」怎么办?BugValidator 自动生成一个能触发这个问题的测试用例:根据反例执行路径构建输入,运行代码,确认是否真的会崩溃或产生错误,输出带详细执行路径的 bug 报告。
实验与结果
实验设置
FM-Agent 在 4 个大规模系统上评估,这些系统均由不同的 AI 编码 Agent 开发,覆盖编译器、深度学习框架、操作系统、数据库等多种领域:
| 系统 | 类型 | 代码行数 | 函数数量 |
|---|---|---|---|
| CCC (Claude's C Compiler) | 编译器 | 143k | 4,957 |
| VibeTensor | 深度学习框架 | 108k | 3,031 |
| VibeOS | 操作系统 | 15k | 452 |
| Bespoke OLAP | 数据库 | 11k | 109 |
| 总计 | - | 277k | 8,549 |
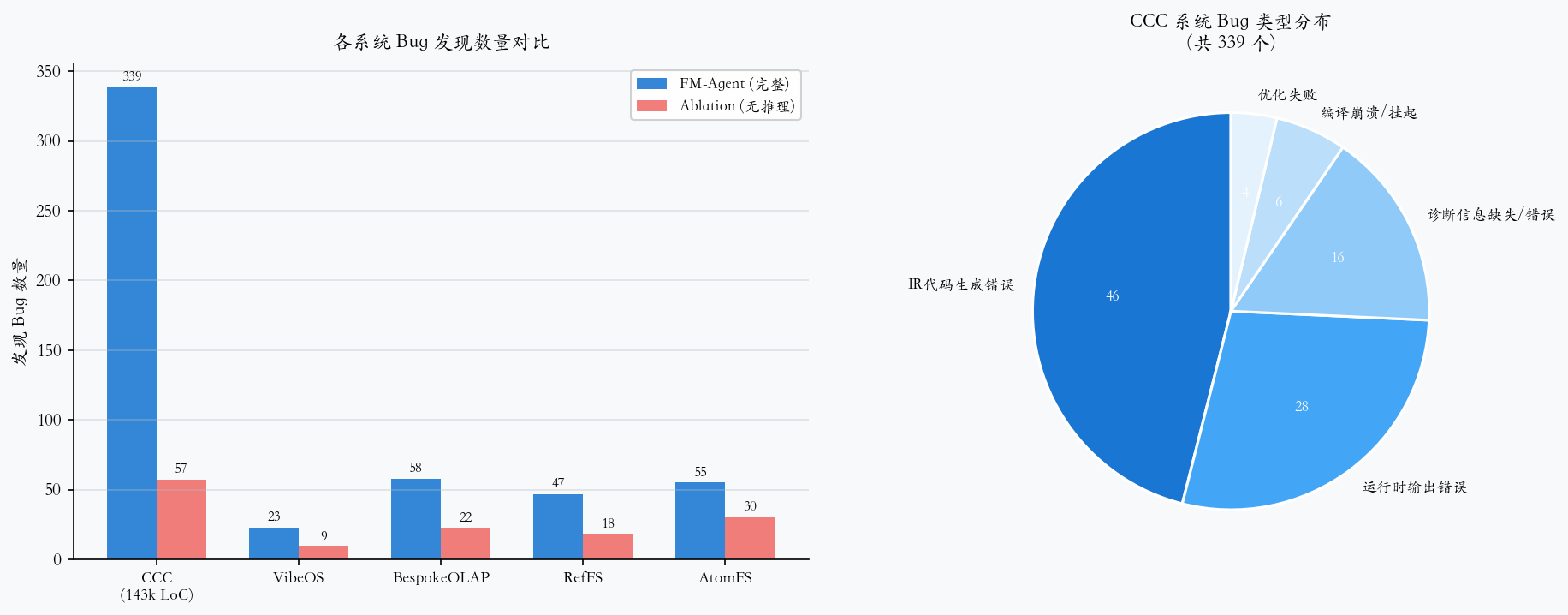
Bug 发现能力
尽管这些系统已经经过开发者测试(集成测试、单元测试、差分测试、多 Agent 代码审查),FM-Agent 仍然发现了 522 个新 bug:
| 系统 | Bug 数量 |
|---|---|
| CCC | 339 |
| VibeTensor | 141 |
| VibeOS | 23 |
| Bespoke OLAP | 19 |
CCC 编译器 Bug 类型分布:
- 111 个导致 IR 级别代码生成错误
- 68 个涉及运行时输出错误
- 39 个导致诊断消息缺失或错误
- 14 个导致编译崩溃或挂起
- 9 个涉及编译优化问题
VibeTensor Bug 类型分布:
- 50 个导致执行结果静默错误(张量值/形状/数据类型)
- 51 个涉及错误处理缺失或错误
- 19 个导致内存安全问题(如内存泄漏)
- 3 个导致程序崩溃
消融实验
论文还做了消融实验来验证各组件的贡献。在 CCC 编译器上,如果只让 LLM 读代码写规格(不使用自顶向下范式),只发现 57 个 bug;而使用完整 FM-Agent 后发现了 339 个 bug——提升近 6 倍。
这说明:自顶向下的规格推导 + Hoare 式推理是两个关键创新点,缺一不可。
可扩展性
整个验证过程在 16 核机器上耗时约 2 天,消耗约 34 亿 token。关键在于分层并行机制:
- CCC 被分解为 13 个阶段,每阶段平均 10 层
- VibeTensor 被分解为 12 个阶段,每阶段平均 7 层
- 不同阶段的规格可以并行生成,同层函数也可以并行处理
启示与思考
我想这 paper 最有意思的地方不是「发现了多少 bug」,而是它重新定义了人机协作的边界。过去我们总觉得形式化验证的瓶颈在于「证明太难」,所以把所有努力都放在自动化证明技术上。但这 paper 指出真正的瓶颈其实是规格本身——谁来写规格?规格从哪里来?
当 LLM 生成代码的时候,规格和代码是一起「涌现」的,而不是先有规格后有代码。这打破了几十年来「规格先行」的软件工程范式。FM-Agent 的回答是:别写了,让 LLM 从使用者的角度反推规格。这个思路其实很接近 TDD(测试驱动开发)的精神——先看调用者期望什么,再反推被调者的契约。
不过我也有几个疑虑:自然语言规格的模糊性怎么解决?当 LLM 推理出错(false positive)时,开发者怎么快速定位是规格写错了还是推理过程错了?这些问题 paper 没有给出很好的答案。但无论如何,FM-Agent 指出了一个有潜力的方向:在 LLM 时代,形式化验证也许真的可以 Scale。