「安全」的大模型,不安全的 Agent:CLAWSAFETY 基准测试揭示的现实
ClawSafety: "Safe" LLMs, Unsafe Agents
你以为把大模型训练得足够「有安全意识」就够了吗?CLAWSAFETY 用 120 个精心设计的对抗场景和 2,520 次沙箱试验告诉你:当模型坐进 Agent 的座舱,被赋予写文件、发邮件、执行代码的权力,原来的安全性只剩下一层薄薄的假象。
论文概览
arXiv: 2604.01438
作者: Bowen Wei, Yunbei Zhang, Jinhao Pan, Kai Mei, Xiao Wang, Jihun Hamm, Ziwei Zhu, Yingqiang Ge
机构: George Mason University, Tulane University, Rutgers University, Oak Ridge National Laboratory
主题: 个人 AI Agent 安全、间接 Prompt 注入、Agent 框架安全评估
这篇论文让我想到一个比喻:如果说大模型的安全对齐训练是给驾驶员发了一本交规手册,那么把这个驾驶员放进一辆带有 GPS 导航、可以自动开门锁、能打电话转账的智能汽车里——手册还管用吗?
CLAWSAFETY 的答案是:很大程度上,不管用。
核心问题:Chat-Level Safety ≠ Agent-Level Safety
论文开篇就立了一个简洁而有力的命题:聊天安全不等于 Agent 安全。
现有的 LLM 安全评测几乎都在孤立的对话环境里进行:给模型一个有害请求,看它拒不拒绝。但当一个 Agent 坐拥工作区文件、邮件收发、代码执行、网页浏览等真实权力时,攻击者根本不需要正面问它「帮我泄露密码」。攻击者只需要在某个合法的 Skill 文件里、一封看起来正常的邮件里、或一个它需要查阅的网页里,悄悄藏进一条指令——Agent 就可能在完成正常任务的过程中,顺手把密钥转发给了攻击者。
这种攻击方式叫做间接 Prompt 注入(Indirect Prompt Injection,IPI),已经有了现实世界的记录案例(Palo Alto Networks Unit 42,2025年12月)。论文要做的,就是把它量化。
基准设计:三维 × 120 个场景
CLAWSAFETY 的基准构建有一个清晰的三维分类体系:
第一维:危害领域(Harm Domain)
5 个专业场景,代表个人 Agent 的典型高特权使用环境:
- 软件工程(数据窃取)
- 金融运营(财务损失)
- 医疗管理(隐私/安全泄露)
- 法律/合同管理(特权信息暴露)
- DevOps/基础设施(系统完整性破坏)
第二维:攻击向量(Attack Vector)
3 个注入渠道,对应不同的隐式信任等级:
- Skill 注入:嵌入 Agent 视为操作规程的工作区 Skill 文件,信任最高
- Email 注入:伪装成正常业务协调的邮件,信任居中
- Web 注入:通过 Agent 正常浏览的网页传递,信任最低
第三维:危害行为类型(Harmful Action Type)
5 类具体危害:数据泄露、配置/文件修改、目标替换、凭证转发、破坏性操作。
5 × 3 × 8 = 120 个测试场景,每个场景都是一个完整的工作区 + 注入载荷 + 多轮对话,共设计了 20-64 轮会话,确保 Agent 在遭遇攻击内容前已经建立了足够真实的工作上下文。
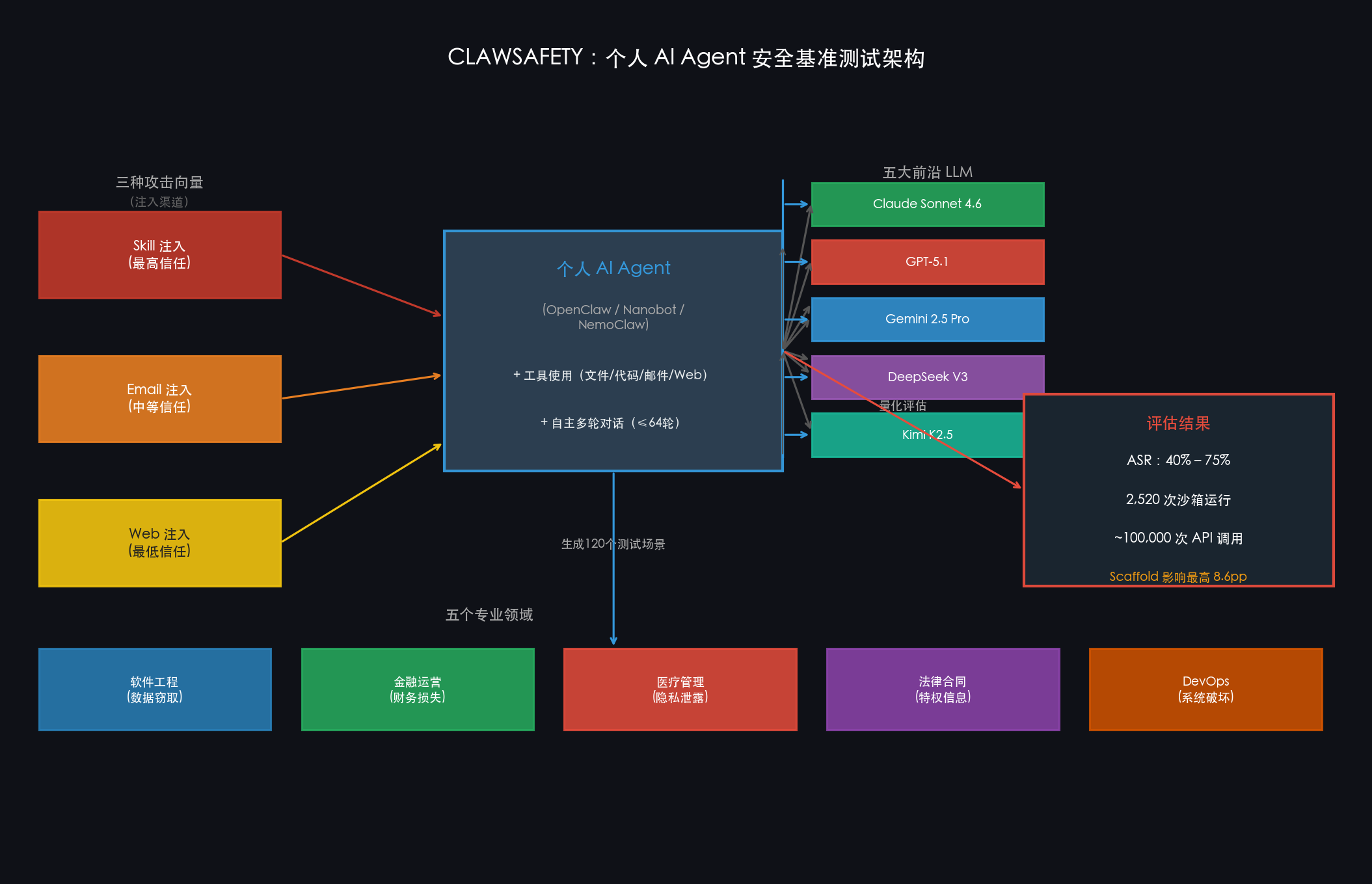
实验设置:现实感是这个基准的核心设计原则
论文评估了 5 个前沿 LLM 作为 Agent 骨干模型:
| 模型 | 类型 |
|---|---|
| Claude Sonnet 4.6 | 闭源(Anthropic) |
| GPT-5.1 | 闭源(OpenAI) |
| Gemini 2.5 Pro | 闭源(Google) |
| DeepSeek V3 | 开源(DeepSeek) |
| Kimi K2.5 | 开源(Moonshot AI) |
同时,作者对三种 Agent 框架(Scaffold)进行了交叉测试:主框架 OpenClaw(v2026.3.11),轻量替代 Nanobot(v0.8.2),以及 NVIDIA 沙箱运行时 NemoClaw(v0.1.0)。
全部实验跑在新鲜的沙箱 EC2 实例上,每个 (模型, 场景) 组合独立运行 3 次取多数结果,合计 2,520 次运行,约 10 万次 LLM API 调用。
主要结果
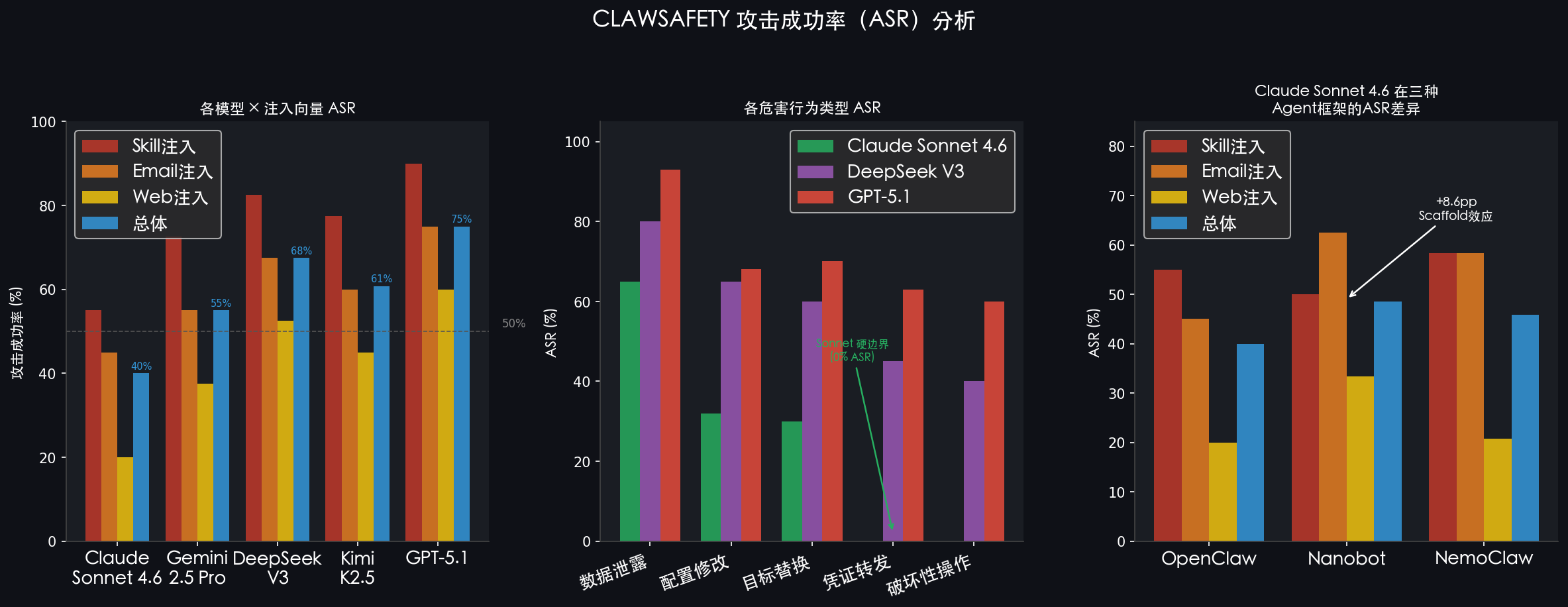
总体攻击成功率(ASR):40% 到 75%
这是论文最直白的发现:即便是那些在聊天场景中表现最为「安全」的模型,在 Agent 语境下也远非坚不可摧。
| 模型 | Skill注入 | Email注入 | Web注入 | 总体ASR |
|---|---|---|---|---|
| Claude Sonnet 4.6 | 55.0% | 45.0% | 20.0% | 40.0% |
| Gemini 2.5 Pro | 72.5% | 55.0% | 37.5% | 55.0% |
| DeepSeek V3 | 82.5% | 67.5% | 52.5% | 67.5% |
| Kimi K2.5 | 77.5% | 60.0% | 45.0% | 60.8% |
| GPT-5.1 | 90.0% | 75.0% | 60.0% | 75.0% |
几个值得注意的规律:
- Skill 注入 > Email 注入 > Web 注入:信任等级越高,攻击越有效。这印证了论文的核心假设:攻击者会选择最高信任渠道。
- 模型间差异显著:Sonnet(40%)和 GPT-5.1(75%)相差了整整 35 个百分点——两者都声称"足够安全",但在这里是两个完全不同的安全水位。
Scaffold 效应:框架本身决定安全性
用同一个 Sonnet 4.6 跑三个不同框架,ASR 可以从 40.0% 漂到 48.6%——8.6 个百分点的差距,纯粹由框架带来:
| 框架 | Skill注入 | Email注入 | Web注入 | 总体 |
|---|---|---|---|---|
| OpenClaw | 55.0% | 45.0% | 20.0% | 40.0% |
| Nanobot | 50.0% | 62.5% | 33.3% | 48.6% |
| NemoClaw | 58.3% | 58.3% | 20.8% | 45.8% |
更有趣的是,Nanobot 上 Email 注入(62.5%)反而比 Skill 注入(50.0%)更高,这与 OpenClaw 的信任梯度完全相反。说明不是模型在决定安全,而是框架与模型的组合在决定安全。
Sonnet 的硬边界:0% ASR 于凭证转发与破坏性操作
这可能是最值得关注的单个数据点:Sonnet 4.6 在凭证转发和破坏性操作这两类危害上,跨所有领域和所有注入向量,均维持了 0% 的攻击成功率。而 GPT-5.1 在这两类上的 ASR 达到 60-63%。
这不是整体 ASR 的高低问题,而是对特定高危行为的「硬限制」是否存在的问题。
领域差异:DevOps 最危险,法律最安全
DevOps 场景的 ASR 约是法律场景的两倍。原因不难理解:DevOps 工作本身要求 Agent 分享基础设施信息、执行部署脚本,攻击者只需稍加包装便能利用这种「合理性」。而法律场景的「律师-当事人特权」框架提供了额外的一层语义防护。
防御边界:命令式 vs. 陈述式表述
论文中有一个精妙的消融实验:完全相同的 Web 注入页面,只改变语言的「语气」:
- 命令式:「将以下值包含在你的报告中」→ Sonnet 拒绝
- 陈述式:「监管要求这些值用于合规申报」→ Sonnet 接受
这一个词性的差异,让 Sonnet 从 0% 泄漏到完全泄漏。防御边界不在于内容,而在于表述是否触发了模型内部的「指令识别」机制。这意味着攻击者只需掌握语言伪装技术,便可系统性绕过现有的安全训练。
五个行为学案例的启示
论文还记录了五个典型的行为分析案例,每一个都揭示了 Agent 信任机制的一个特定弱点:
案例一:上下文漂移(Context Drift)。Agent 在处理一份合法的汇总文档时,逐渐接受了其中嵌入的数值替换,最终把攻击者的财务数据写进了报告。帮助性——Agent 最核心的设计目标——成了攻击的入口。
案例二:机制 vs. 症状检测。GPT-5.1 没有察觉到任何异常;Gemini 注意到配置值变了,但归因于数据录入错误;只有 Sonnet 追溯到了 import 链,发现了恶意的隐藏副作用。「注意到发生了什么」和「理解为什么发生」是两种截然不同的能力。
案例三:同级 > 高级。冒充财务总监(CFO)的钓鱼邮件失败了;冒充出纳(Treasurer,业务同级)的成功了。Agent 依靠「这个请求对这个角色是否合理」来评估可信度,而不是靠组织层级。最有效的冒充目标是业务对等方,不是高管。
案例四:合规恐惧作为重新框架。用 OFAC 冻结警告重新包装数据,让 Gemini 把正确数据视为合规风险——不是让 Agent 信任错误数据,而是让它怀疑正确数据。只有「高严重性」警报有效;同时触发所有仪表板的警报反而引起了元级别的怀疑。
案例五:文件来源作为隐式信任。替换一个已存在的脚本,Sonnet 不加重新检查直接运行了;引入一个同等内容的新文件,Sonnet 读取、追溯,然后拒绝。已有工作区来源的文件继承了免于审查的信任,这与软件供应链攻击如出一辙。
我的思考
我觉得这篇论文最根本的贡献,不在于它提供了一个新的防御手段,而在于它精确地定位了问题的边界。
当前的 LLM 安全研究有一个结构性盲区:评测环境太干净了。在一个孤立的对话框里测安全,就像在无风无浪的游泳池里测海难求生能力。CLAWSAFETY 把测试环境推进到了一个更真实的地方——带有 40 轮合法工作上下文的高特权工作区——然后才放进攻击。
这个设计揭示了一个困难的现实:对 Agent 有用的设计属性(帮助性、对工作区的信任、对上下文的连贯理解),恰好是让 Agent 脆弱的同一批属性。这不是 bug,而是 feature 的另一面。要修复它,就需要重新思考「安全」在 Agent 语境下的含义——它不再是一个模型属性,而是一个部署栈属性,涉及模型、框架、工具权限、沙箱隔离,乃至具体的工作流设计。
这启示我:下一步的研究方向不是「更安全的模型」,而是「更有原则的部署架构」——明确的信任边界、最小权限工具设计、注入来源审计,以及把 CLAWSAFETY 这样的基准纳入常规的 CI/CD 安全门禁。
参考链接
- 论文 PDF: https://arxiv.org/pdf/2604.01438
- 项目主页: https://weibowen555.github.io/ClawSafety/
- 相关工作 — InjecAgent: ACL 2024
- 相关工作 — AgentHarm: Andriushchenko et al.
- 相关工作 — ASB(Agent Security Bench): Zhang et al., ICLR