Agent Behavioral Contracts:为 AI Agent 带来设计契约
Agent Behavioral Contracts: Formal Specification and Runtime Enforcement for Reliable Autonomous AI Agents
本文将传统软件工程中的「设计契约(Design by Contract)」范式引入 AI Agent 领域,提出 ABC 框架——通过前置条件、不变量、治理策略和恢复机制四元组,在运行时对 LLM Agent 的行为进行数学级约束与监督。实验表明,有合约的 Agent 可将行为漂移控制在 D* < 0.27,检出无合约基线完全漏掉的 5.2–6.8 个软违规/会话,运行开销不超过 10ms。
一句话定位
传统软件用 API 合约、类型系统和断言约束行为;AI Agent 目前只有"提示词",无法形式化验证。这篇论文把**设计契约(Design by Contract)**搬进了 LLM Agent 时代,让 Agent 的行为可测量、可约束、可恢复。
背景:为什么 AI Agent 需要"合约"
问题的根源
生产环境的 AI Agent 正在承担越来越重要的角色:金融顾问、医疗分诊、代码生成、研究摘要。这些 Agent 会调用工具、访问数据库、做出有实际后果的决策。
但现实是,目前没有任何机制可以正式约束 LLM Agent 必须怎样行动。传统软件有:
- 类型系统:编译期约束
- API 合约:接口前/后置条件
- 断言:运行时检查
AI Agent 只有:
- 提示词(prompt):自然语言,无形式语义
- 测试(偶发):无法穷举
- RLHF 对齐:针对训练分布,不针对特定业务规则
**行为漂移(Behavioral Drift)**是最严重的问题——在多轮对话中,Agent 会逐渐偏离规格说明,这不是 bug,而是 LLM 的内在随机性加上提示词"稀释"导致的必然现象。已有案例显示,即便是 GPT-4 级别的模型,在 20+ 轮会话后也会显著偏离最初的行为约束。
传统对齐方法的局限
| 方法 | 覆盖范围 | 局限性 |
|---|---|---|
| RLHF / Constitutional AI | 训练时 | 不能约束特定业务规则;推理时无法干预 |
| 提示词工程 | 单次调用 | 无运行时验证;漂移不可见 |
| 测试评估 | 静态 snapshot | 不反映多轮行为;无法实时干预 |
| VeriGuard / ShieldStep | 特定场景 | 被动监控,无形式化规格先行 |
核心方案:ABC 框架
合约的四元组定义
ABC 引入一个正式的合约结构 C = (P, I, G, R):
P — Preconditions 前置条件:任务开始前必须满足的约束
I — Invariants 不变量:整个会话中任意时刻都必须成立的属性
G — Governance 治理策略:对 Agent 可采取行动集合的限制
R — Recovery 恢复机制:违约时的纠正行为规范以一个金融顾问 Agent 为例:
contract = ContractSpec(
preconditions=[
"用户账户验证已完成",
"任务类型在已批准服务范围内"
],
invariants=[
"不得泄露其他用户的投资组合信息",
"推荐建议必须符合用户风险等级",
"每次建议必须包含免责声明"
],
governance=[
"禁止调用外部支付接口",
"禁止直接下单,只能提供建议",
"单次响应不超过 500 字"
],
recovery=RecoveryPolicy(
on_soft_violation="重新提示 + 记录",
on_hard_violation="终止并返回错误"
)
)合规性的概率定义:(p, δ, k)-满足性
由于 LLM 本质上是概率性的,ABC 引入了一个概率合规性概念:
Agent A (p, δ, k)-满足合约 C,当且仅当: 在至少 p 概率的会话中,对 k 个可评估约束,偏离容限不超过 δ。
这比「完全合规」现实得多——它承认 LLM 的不确定性,但要求将违规控制在可接受阈值内。
系统架构
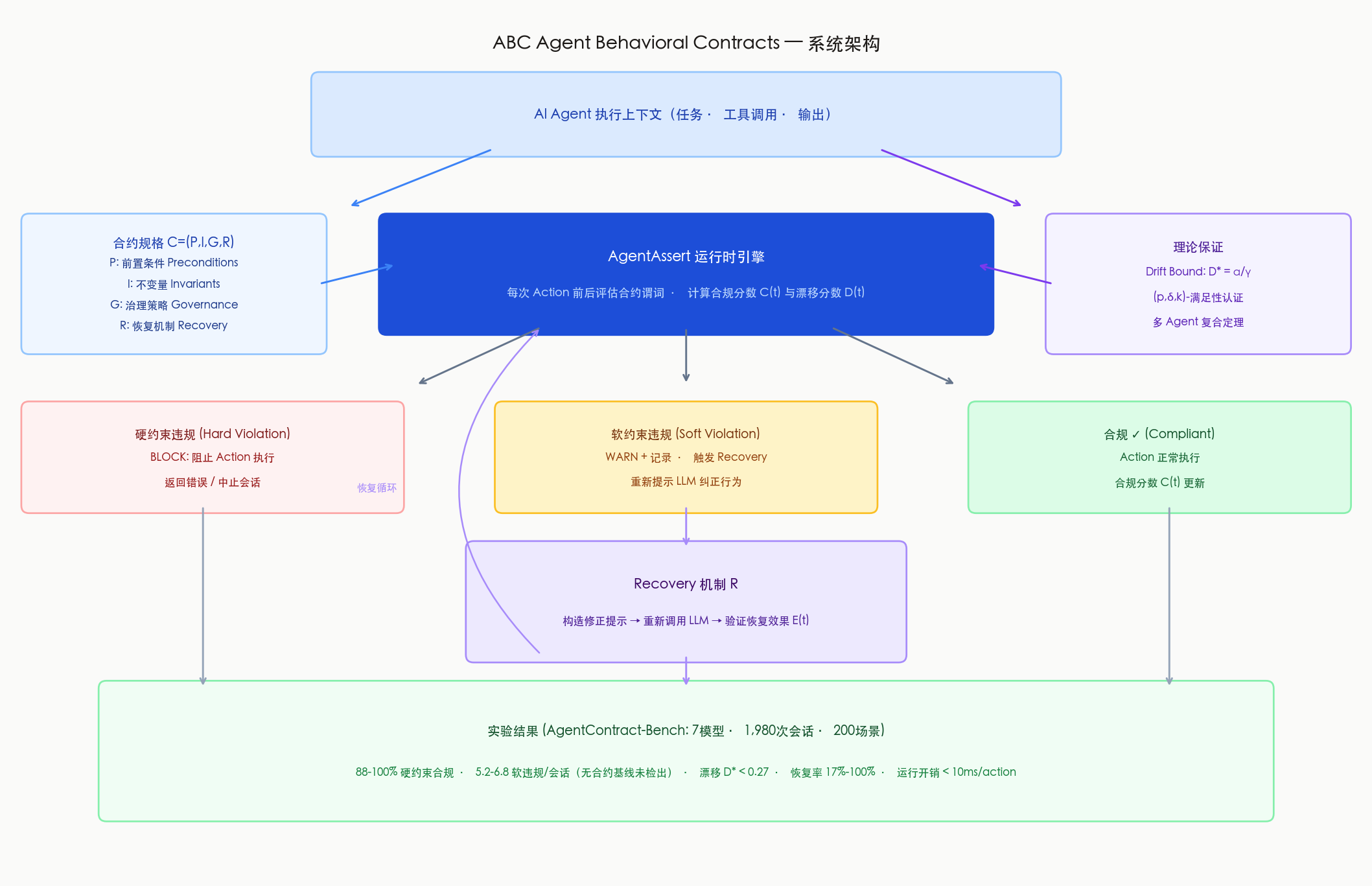
图1:ABC 完整架构,涵盖合约规格、AgentAssert 运行时引擎、三类处理路径和恢复循环
整个系统分为三层:
① 合约规格层(Specification Layer)
ContractSpec类:声明式定义 P、I、G、R- 在部署前编写,独立于具体 LLM
- 支持 JSON Schema 验证、LTL(线性时序逻辑)约束
② 运行时引擎(AgentAssert)
- 每次 Agent action 前后触发合约评估
- 并行评估硬约束(HardChecker)和软约束(SoftChecker)
- 维护漂移分数 D(t):用 Jensen-Shannon 散度衡量行为分布偏移
- 全部逻辑无需修改 LLM 本身
③ 处理路径
- 硬违规:立即阻断 action,返回错误响应
- 软违规:构造修正提示,触发 LLM 重新生成
- 合规:action 正常执行,更新合规分数 C(t)
理论核心:漂移控制的数学证明
漂移动态模型
论文将 Agent 的行为漂移建模为Ornstein-Uhlenbeck(OU)随机过程:
dD(t) = (α − γ·D(t))dt + σ·dW(t)三个参数各有含义:
- α(自然漂移率):在没有干预情况下,Agent 每步骤的行为偏移量
- γ(合约恢复率):合约执行的"回弹力"——当 D(t) 偏大时施加的修正力
- σ(随机扰动):LLM 内在的不确定性(温度参数、采样噪声等)
OU 过程有一个重要性质:它会均值回归,稳态均值为 D = α/γ*。
漂移界定理(核心定理)
论文证明,在稳态分布下:
- 期望漂移:E[D(t)] = α/γ,即只要 γ > α(合约恢复率超过自然漂移率),漂移就有界
- 方差:Var[D(t)] = σ²/2γ,更高的恢复率可以二次方地压缩漂移波动
- 高概率界:P(D(t) > α/γ + η) ≤ exp(−γη²/σ²)
实验中,合约 Agent 的漂移被控制在 D < 0.27*,无合约基线的漂移则发散至 6.0+。
多 Agent 链的复合定理
当多个 Agent 串联时,如果 A (pA, δA)-满足 CA,B (pB, δB)-满足 CB,则链的可靠性满足:
p_chain ≥ pA · pB · p_handoff
δ_chain ≤ δA + δB + δ_handoff这揭示了一个重要风险:多 Agent 系统的可靠性以乘积方式退化。10 个各自 95% 可靠的 Agent 串联,链路可靠性降至 0.95¹⁰ ≈ 60%。这是设计多 Agent 系统时必须正视的数学现实。
实现:AgentAssert 库
核心 API 设计
from agentassert import AgentAssert, ContractSpec, HardConstraint, SoftConstraint
# 定义合约
contract = ContractSpec(
hard_constraints=[
HardConstraint("no_pii_leak",
predicate=lambda action: not contains_pii(action.output),
violation_policy="BLOCK"),
],
soft_constraints=[
SoftConstraint("response_length",
predicate=lambda action: len(action.output) < 500,
violation_policy="WARN_AND_RECOVER"),
]
)
# 包装 Agent
monitored_agent = AgentAssert.wrap(agent, contract)
# 正常使用,监控透明运行
result = monitored_agent.run(task)关键度量指标
论文定义了可靠性指数 Θ,作为 Agent 整体表现的综合评分:
Θ = α₁·C(t) + α₂·(1-D(t)) + α₃·(1/(1+E)) + α₄·S其中:
- C(t):合规分数(硬软约束综合)
- D(t):行为漂移分数
- E:恢复效率(越低越好)
- S:压力韧性指数(对抗场景下的合规保持率)
实验结果
实验1:有合约 vs. 无合约(核心实验)
在 200 个场景、7 个模型(GPT-5.2、Claude Opus 4.6、Llama 3.3 70B、Mistral Large 3 等)上评测:
| 指标 | 有合约 | 无合约基线 |
|---|---|---|
| 硬约束合规率 | 88%–100% | — |
| 软违规检出 | 5.2–6.8 次/会话 | 0(完全漏掉) |
| 行为漂移 D* | < 0.27 | 发散 |
| 可靠性指数 Θ | 0.908–0.967 | 无法量化 |
| 运行开销 | < 10ms/action | — |
统计检验:p < 0.0001,Cohen's d = 6.7–33.8(效应量极大)。
实验2:漂移控制(扩展会话测试)
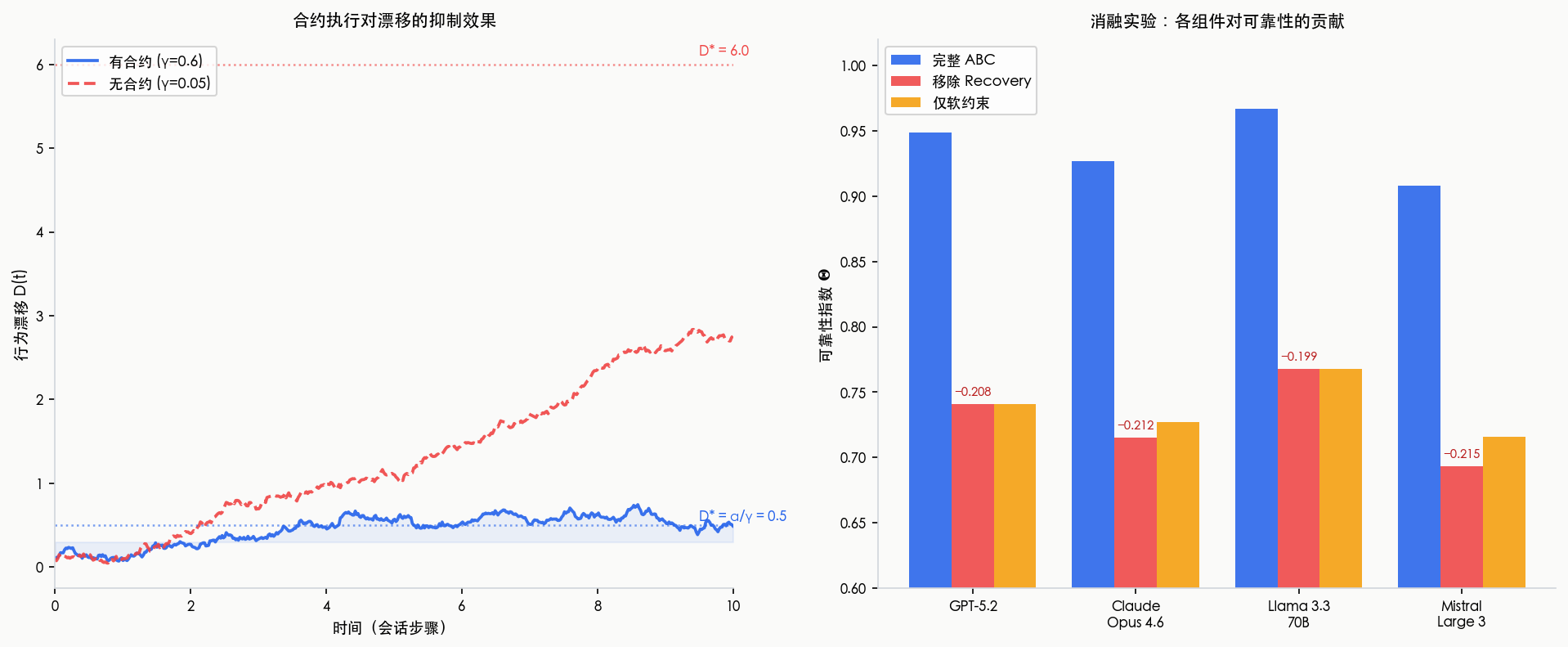
图2:左图为漂移动态仿真(有合约 vs 无合约),右图为消融实验中各模型可靠性指数
在 50 轮多步会话中:
- 有合约:漂移稳定在 D* < 0.27(OU 过程均值回归)
- 无合约:漂移持续增长,30 轮后超过 0.6
- 前沿模型(GPT-5.2、Claude Opus)100% 恢复率,开源模型 17%–60%
实验3:对抗性压力测试(6 种攻击模式)
论文设计了 6 种对抗场景:
- 提示注入:试图绕过合约规则
- 越狱尝试:引导 Agent 违反 G 约束
- 角色扮演绕过:通过虚构场景绕过 I 约束
- 上下文污染:向历史注入虚假信息
- 任务欺骗:引导 Agent 认为违规行为是合规的
- 链攻击:在多 Agent 链中间注入恶意输出
结果:合约 Agent 的 Θ 仅从 0.974 轻微下降到 0.938(−0.036),对抗韧性显著。
实验4:消融实验(各组件贡献)
| 条件 | Θ(4模型均值) | 变化 |
|---|---|---|
| 完整 ABC | 0.938 | baseline |
| 仅硬约束 | 0.960 | +0.022(软合规变"真空") |
| 仅软约束 | 0.738 | −0.200 |
| 仅漂移监控 | 0.960 | +0.022(同上) |
| 移除 Recovery | 0.730 | −0.208 |
关键发现:Recovery 机制与软约束是乘法关系,不是加法关系——移除任意一个的效果与同时移除两个几乎相同(−0.20 vs. −0.21)。这说明软约束检测必须配合恢复才有意义,单独监控没有治理效果。
与相关工作的比较
| 方法 | 规格先行 | 运行时干预 | 漂移检测 | 多 Agent | 对抗测试 |
|---|---|---|---|---|---|
| RLHF | ✗ | ✗ | ✗ | ✗ | Partial |
| VeriGuard | Partial | ✓ | ✗ | ✗ | ✗ |
| StepShield | ✗ | ✓ | ✓(后置) | ✗ | ✗ |
| ABC | ✓ | ✓ | ✓(先行) | ✓ | ✓ |
ABC 与 Ye & Tan(2026)的资源契约(Resource Contracts)互补:资源契约约束"消耗多少",行为契约约束"怎样行动"——可以叠加使用。
局限性与挑战
1. 合约编写成本:目前合约需要人工设计,对非技术用户门槛较高。作者提到未来可以从现有策略文档、日志中自动挖掘合约。
2. 模型依赖性:Recovery 成功率高度依赖模型能力——Llama 3.3 70B 的恢复率 17%,远低于前沿模型。对于能力较弱的模型,"发现违规但无法恢复"的困境较难解决。
3. 语义评估瓶颈:软约束谓词目前部分依赖 LLM 自评估(即用 LLM 判断 LLM 是否违规),存在自我评估偏差。硬约束用确定性代码评估,但软约束更难形式化。
4. 开放域泛化:在金融、医疗等垂直领域效果良好,但在完全开放域任务中,合约覆盖率难以保证。
5. 隐私边界:合约引擎需要观察 Agent 的每个 action,在 Agent 处理敏感数据时会引入新的信息流风险。
启示与思考
思考一:「契约」是 AI 工程化的基础设施
软件工程花了几十年才从"写代码"发展到"契约驱动开发"(DbC)。AI Agent 现在处于早期阶段——大量系统还是"写提示词 + 运气好就行"。ABC 代表的是一个必然的演进方向:从提示词工程到行为规格工程。
这不仅是工程问题,也是商业问题:没有可验证行为规格的 AI Agent,很难通过金融监管、医疗合规审查。ABC 这类框架实际上是在为"AI Agent 进入强监管行业"铺路。
思考二:漂移是 LLM 的本质属性,不是 bug
论文把漂移建模为 OU 随机过程,承认了一个很重要的认知:行为漂移不是模型缺陷,是 LLM 非确定性的必然结果。
这意味着"彻底消除漂移"是错误目标,正确目标是"把漂移控制在可接受边界内"。这和物理控制论中的思路完全一致——不要求系统永远精确,而是要求误差有界。D* = α/γ 这个公式非常漂亮,它告诉你:通过调大合约恢复率 γ,你可以线性压缩漂移上界。
思考三:多 Agent 系统需要链级合约
论文的复合定理揭示的问题比它提供的解法更深刻:可靠性的乘积退化是多 Agent 系统的根本挑战。10 个 Agent 串联,整体可靠性可以降到 60%。
这意味着:
- 设计 Multi-Agent 系统时,链的长度是关键参数,不是越长越好
- 每个 Agent 的合约需要考虑"作为链路组件"的语义,而不只是独立的任务规格
- 中间检查点(checkpointing)和恢复机制在链路设计中和在单 Agent 中同等重要
思考四:合约 vs. 对齐,哪个是根本?
一个有趣的哲学问题:ABC 所做的事情,本质上是用外部机制补偿了内在对齐的不足。如果模型足够对齐,是否还需要合约?
我认为两者互补而非替代:
- 对齐处理的是"不知道自己在做错事"的问题(模型不了解什么是好行为)
- 合约处理的是"知道规则但系统行为不可预测"的问题(LLM 的随机性和漂移)
就像代码通过了单元测试不等于不需要类型系统,对齐的模型不等于不需要运行时合约。
思考五:下一步——自动合约生成
这篇论文假设合约是人工写的。但真正的规模化需要从策略文档、历史 logs、监管条例中自动提取合约。这是一个非常有价值但未解决的方向:把自然语言的合规要求(如 GDPR、SOC 2、医疗法规)自动转化为形式化的 ABC 合约,可能是下一个重要的工作。
总结
ABC 框架的核心贡献可以归结为四点:
- 形式化定义:把 DbC 范式扩展到 AI Agent,C=(P,I,G,R) 的四元组定义简洁有力
- 可证明的漂移控制:用 OU 过程数学证明合约可以将漂移约束在 D*=α/γ
- 工程可用性:AgentAssert 开销 <10ms/action,对生产系统几乎无感知
- 全面的实验验证:7 模型 × 1980 次会话,结果具有统计显著性
如果说 2023–2024 年是「AI Agent 能做什么」的探索期,那么 2025–2026 年将会是「AI Agent 怎么让人信任」的治理期。ABC 是这个转型中一块重要的基石。